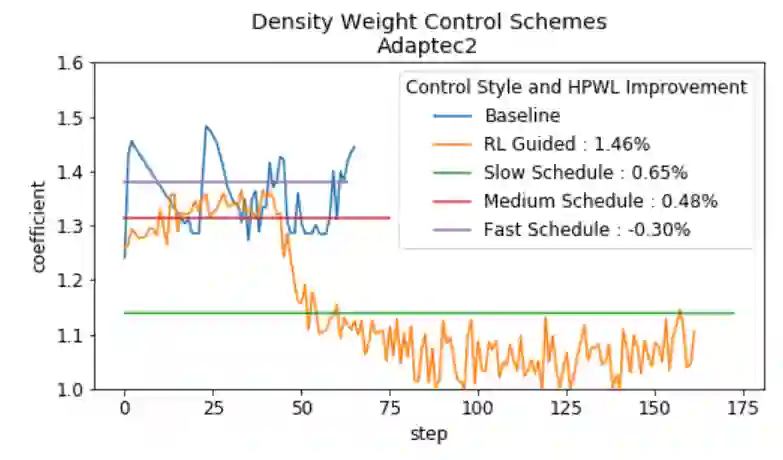
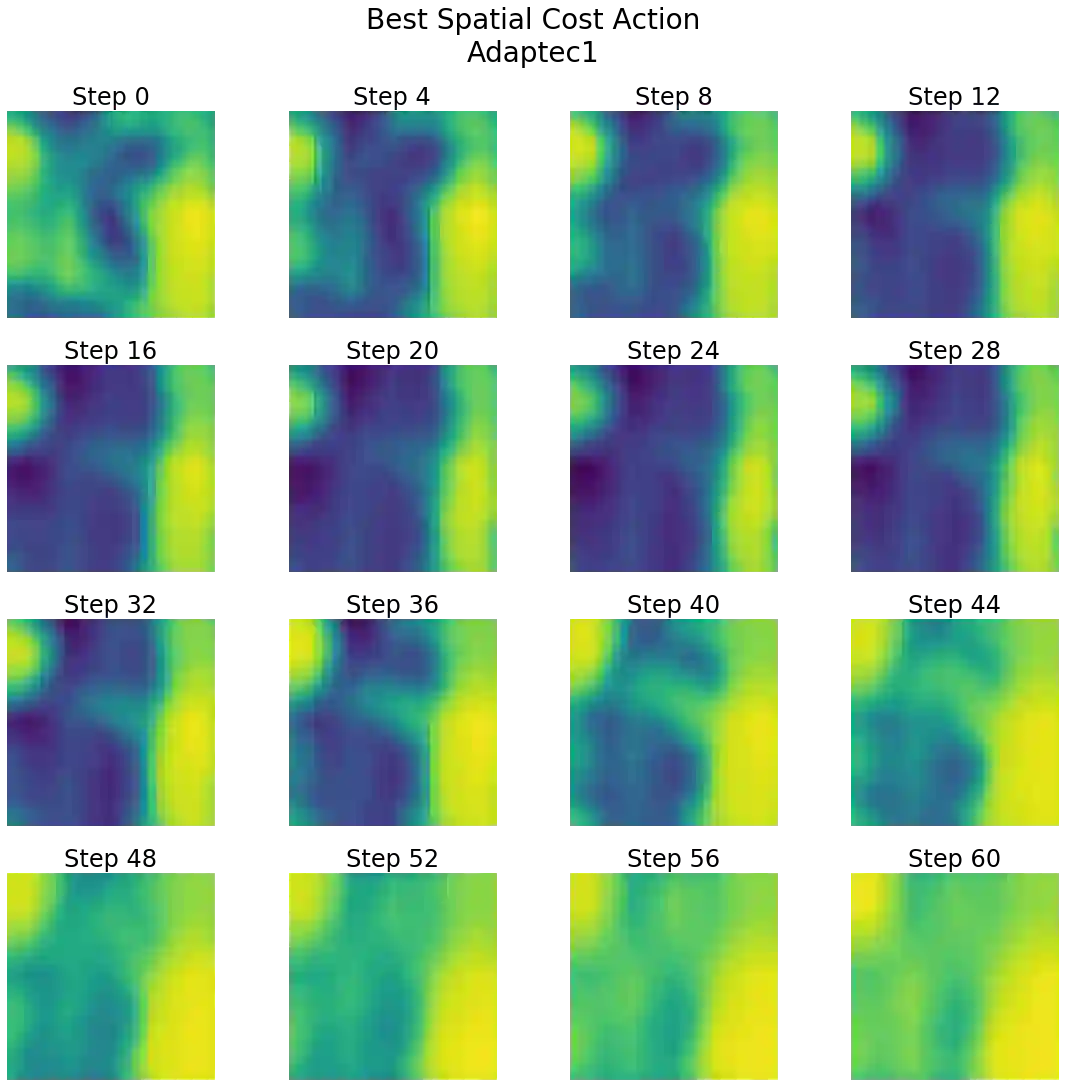
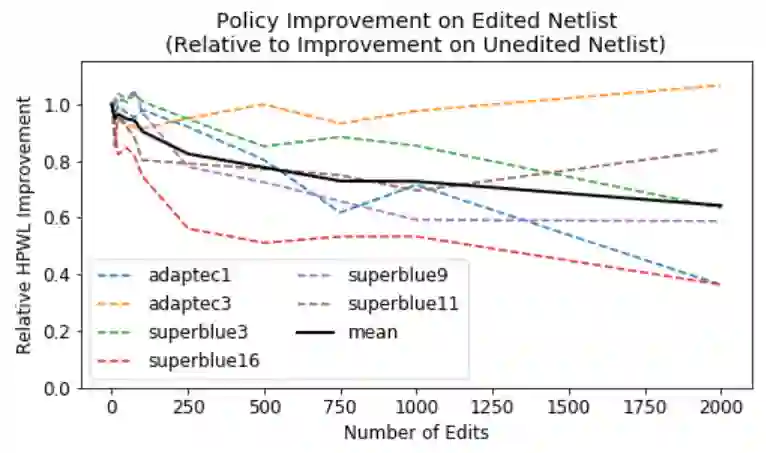
Recent advances in GPU accelerated global and detail placement have reduced the time to solution by an order of magnitude. This advancement allows us to leverage data driven optimization (such as Reinforcement Learning) in an effort to improve the final quality of placement results. In this work we augment state-of-the-art, force-based global placement solvers with a reinforcement learning agent trained to improve the final detail placed Half Perimeter Wire Length (HPWL). We propose novel control schemes with either global or localized control of the placement process. We then train reinforcement learning agents to use these controls to guide placement to improved solutions. In both cases, the augmented optimizer finds improved placement solutions. Our trained agents achieve an average 1% improvement in final detail place HPWL across a range of academic benchmarks and more than 1% in global place HPWL on real industry designs.
翻译:GPU全球加速和详细定位的最新进展缩短了按数量顺序解决问题的时间。 这一进展使我们能够利用数据驱动优化(如强化学习)来努力提高安置结果的最终质量。 在这项工作中,我们提升了最先进的、以力量为基础的全球安置解决方案,并培训了一个强化学习代理机构来改进将半边缘线长度(HPWL)置于最后细节的位置。我们提出了新的控制计划,对安置过程进行全球或局部控制。我们随后培训强化学习代理机构使用这些控制来引导安置改进解决方案。在这两种情况下,增强的优化者都找到了更好的安置解决方案。我们受过培训的代理机构在最终细节上实现了平均1%的改进,将HPWL置于一系列学术基准范围,并将超过1%的HPWL置于全球实际工业设计中。