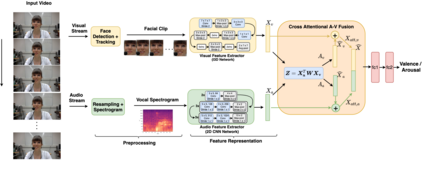
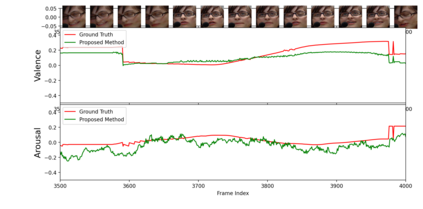
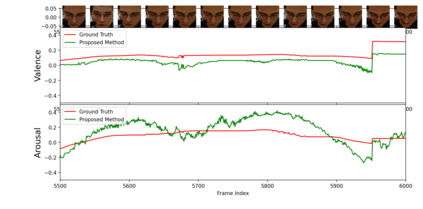
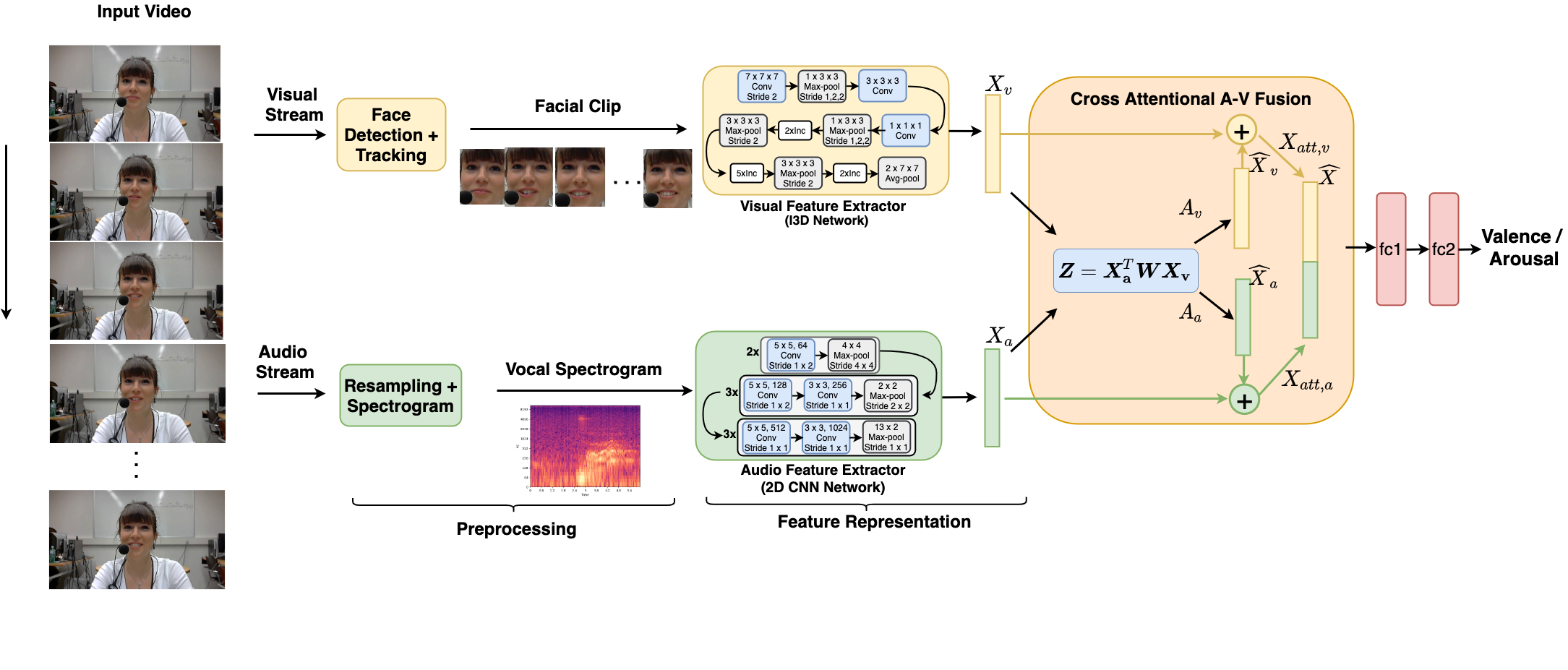
Multimodal analysis has recently drawn much interest in affective computing, since it can improve the overall accuracy of emotion recognition over isolated uni-modal approaches. The most effective techniques for multimodal emotion recognition efficiently leverage diverse and complimentary sources of information, such as facial, vocal, and physiological modalities, to provide comprehensive feature representations. In this paper, we focus on dimensional emotion recognition based on the fusion of facial and vocal modalities extracted from videos, where complex spatiotemporal relationships may be captured. Most of the existing fusion techniques rely on recurrent networks or conventional attention mechanisms that do not effectively leverage the complimentary nature of audio-visual (A-V) modalities. We introduce a cross-attentional fusion approach to extract the salient features across A-V modalities, allowing for accurate prediction of continuous values of valence and arousal. Our new cross-attentional A-V fusion model efficiently leverages the inter-modal relationships. In particular, it computes cross-attention weights to focus on the more contributive features across individual modalities, and thereby combine contributive feature representations, which are then fed to fully connected layers for the prediction of valence and arousal. The effectiveness of the proposed approach is validated experimentally on videos from the RECOLA and Fatigue (private) data-sets. Results indicate that our cross-attentional A-V fusion model is a cost-effective approach that outperforms state-of-the-art fusion approaches. Code is available: \url{https://github.com/praveena2j/Cross-Attentional-AV-Fusion}
翻译:最近,多式分析吸引了人们对感官计算的兴趣,因为它可以提高对孤立的单式方法的情感认知的总体准确性; 最有效的多式联运情感认知技术,有效地利用面部、声音和生理模式等多种和补充性信息来源,提供全面的特征表述; 本文侧重于以从视频中提取的面部和声学模式相结合为基础的维度情感认知,其中可以捕捉复杂的时空关系; 现有的聚变技术大多依赖于经常性网络或常规关注机制,这些网络或机制无法有效地利用视听(A-V)模式的互补性。 我们采用了一种跨预防性聚合方法,以提取A-V模式的突出特征,从而准确预测持续的价值值和振动性。 我们新的跨关注性A-V-聚变模型有效地利用了多种模式的关系。 特别是,它利用了跨州模式中更具共性特征的网络或常规关注机制,从而将共性特征描述组合性特征的表达方式,然后将A-V-V模式组合式组合式组合式组合式组合式组合式组合式组合,用于完全的A-V模式-A-RO-S-al-al-al-al-al-al-al-al-al-al-al-al-al-al-al-al-al-al-al-al-al-al-al-al-al-al-al-al-al-al-al-al-al-al-al-al-al-alisal-al-al-al-al-al-al-al-al-al-al-al-al-al-al-al-al-al-al-al-al-al-al-al-al-al-al-al-al-al-al-al-al-al-al-al-al-al-al-al-al-al-al-al-al-al-al-al-al-al-al-al-al-al-al-al-al-al-al-al-al-al-al-al-al-al-al-al-al-al-al-al-al-al-al-al-al-al-al-al-al-al-al-al-al-al-al-al-al-al-al-al-al-al-al-al-al