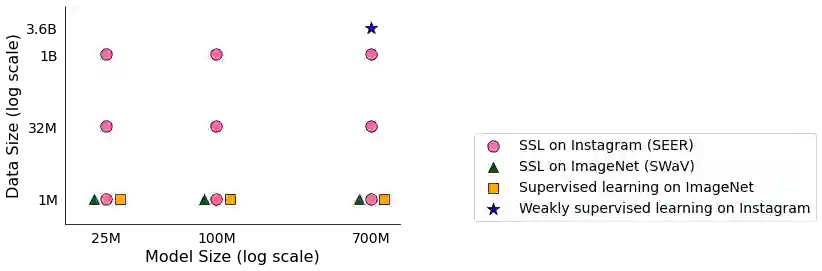
Does everyone equally benefit from computer vision systems? Answers to this question become more and more important as computer vision systems are deployed at large scale, and can spark major concerns when they exhibit vast performance discrepancies between people from various demographic and social backgrounds. Systematic diagnosis of fairness, harms, and biases of computer vision systems is an important step towards building socially responsible systems. To initiate an effort towards standardized fairness audits, we propose three fairness indicators, which aim at quantifying harms and biases of visual systems. Our indicators use existing publicly available datasets collected for fairness evaluations, and focus on three main types of harms and bias identified in the literature, namely harmful label associations, disparity in learned representations of social and demographic traits, and biased performance on geographically diverse images from across the world.We define precise experimental protocols applicable to a wide range of computer vision models. These indicators are part of an ever-evolving suite of fairness probes and are not intended to be a substitute for a thorough analysis of the broader impact of the new computer vision technologies. Yet, we believe it is a necessary first step towards (1) facilitating the widespread adoption and mandate of the fairness assessments in computer vision research, and (2) tracking progress towards building socially responsible models. To study the practical effectiveness and broad applicability of our proposed indicators to any visual system, we apply them to off-the-shelf models built using widely adopted model training paradigms which vary in their ability to whether they can predict labels on a given image or only produce the embeddings. We also systematically study the effect of data domain and model size.
翻译:计算机视觉系统是否同样受益于计算机视觉系统? 这个问题的答案是否也变得日益重要? 计算机视觉系统大规模部署,当计算机视觉系统表现出来自不同人口和社会背景的人之间巨大的性能差异时,可能会引起重大关切。 系统地分析计算机视觉系统的公平性、伤害和偏见是建立对社会负责的系统的重要一步。 为了启动标准化的公平审计,我们提出了三个公平性指标,目的是量化视觉系统的伤害和偏见。 我们的指标使用为公平性评价而收集的现有公开数据集,并侧重于文献中查明的三种主要的伤害和偏见,即有害的标签协会、社会及人口特征的学习程度差异,以及世界各地不同图像上的差异性表现。 我们界定适用于各种计算机视觉模型的精确实验性协议。这些指标是不断演变的公平性调查的一部分,而不是要取代对新的计算机视觉技术的更广泛影响进行彻底分析。 然而,我们认为,这是必要的第一步:(1) 便利在计算机视觉研究中广泛采用和授权的公平性评估,在广泛的社会形象研究中,以及(2) 利用我们所建立的任何具有社会责任感的模型来建立模型。