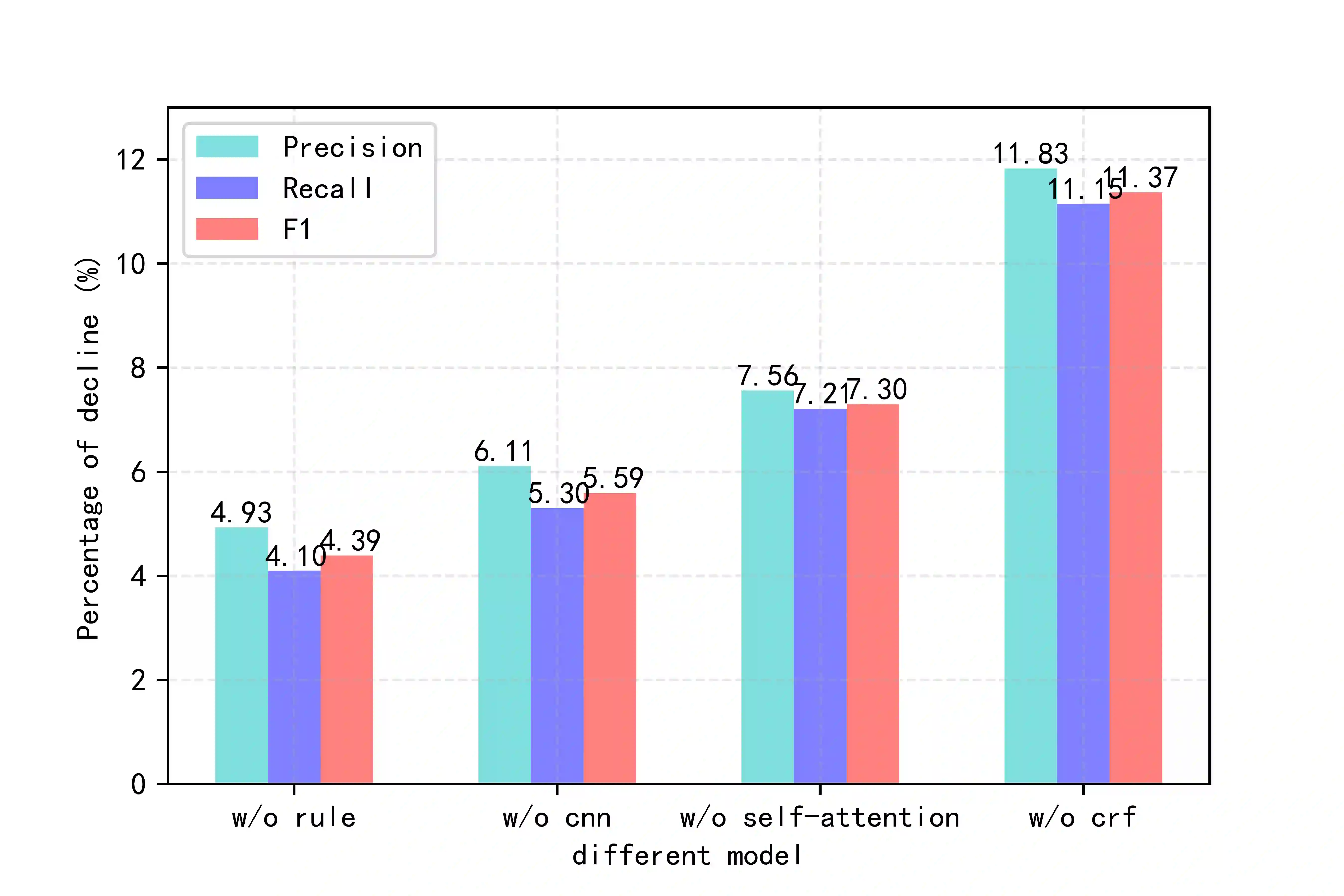
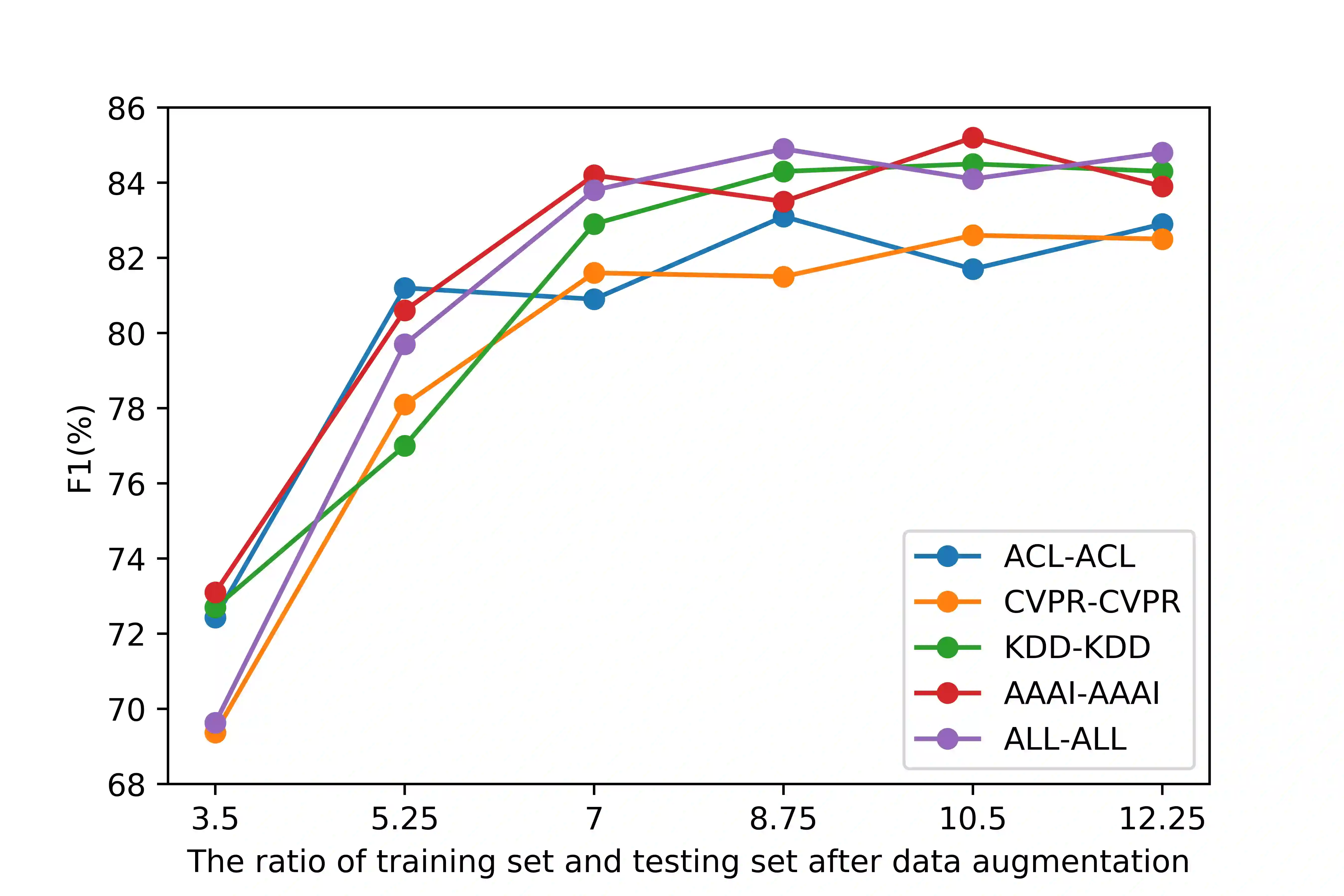
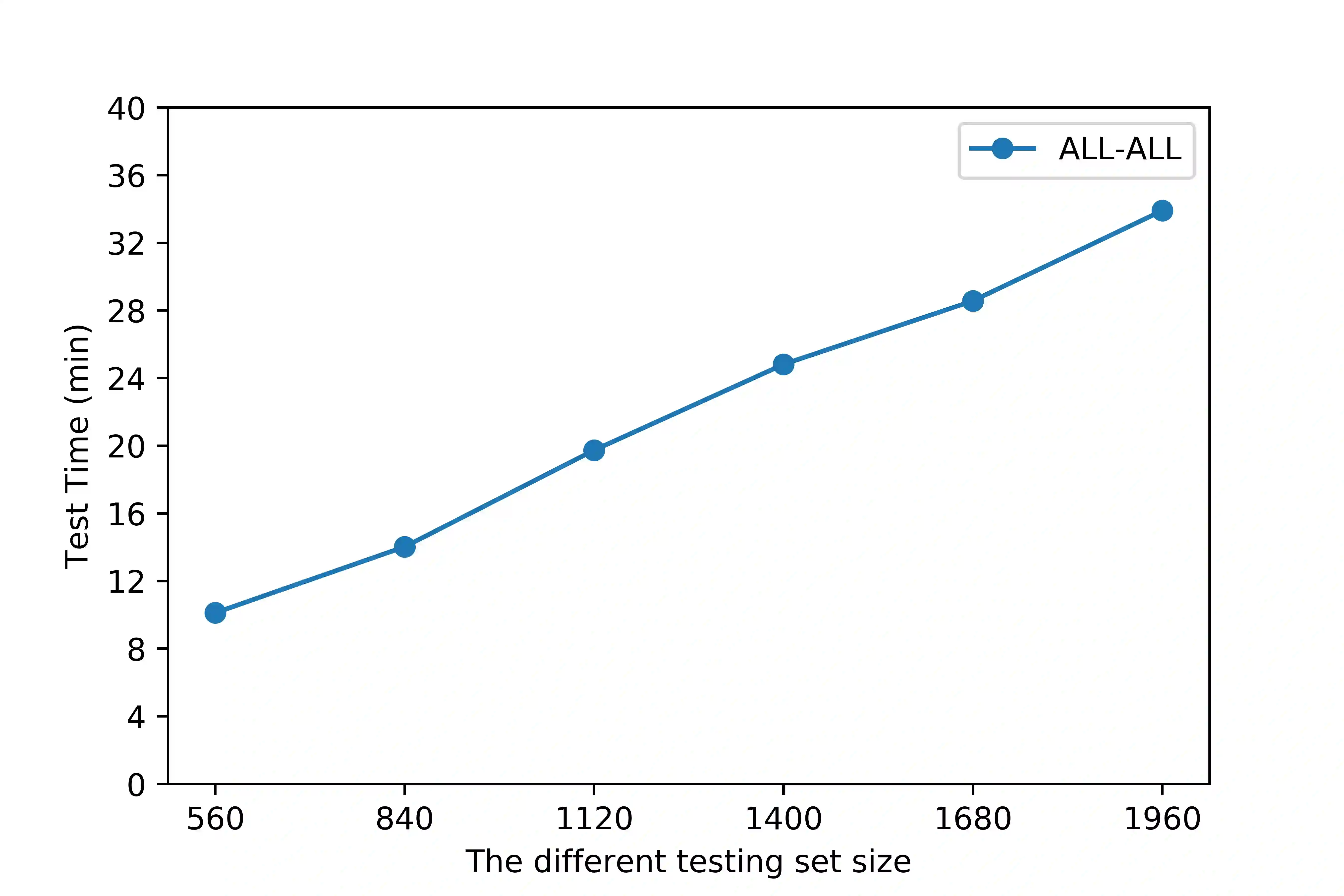
Literature analysis facilitates researchers to acquire a good understanding of the development of science and technology. The traditional literature analysis focuses largely on the literature metadata such as topics, authors, abstracts, keywords, references, etc., and little attention was paid to the main content of papers. In many scientific domains such as science, computing, engineering, etc., the methods and datasets involved in the scientific papers published in those domains carry important information and are quite useful for domain analysis as well as algorithm and dataset recommendation. In this paper, we propose a novel entity recognition model, called MDER, which is able to effectively extract the method and dataset entities from the main textual content of scientific papers. The model utilizes rule embedding and adopts a parallel structure of CNN and Bi-LSTM with the self-attention mechanism. We evaluate the proposed model on datasets which are constructed from the published papers of four research areas in computer science, i.e., NLP, CV, Data Mining and AI. The experimental results demonstrate that our model performs well in all the four areas and it features a good learning capacity for cross-area learning and recognition. We also conduct experiments to evaluate the effectiveness of different building modules within our model which indicate that the importance of different building modules in collectively contributing to the good entity recognition performance as a whole. The data augmentation experiments on our model demonstrated that data augmentation positively contributes to model training, making our model much more robust in dealing with the scenarios where only small number of training samples are available. We finally apply our model on PAKDD papers published from 2009-2019 to mine insightful results from scientific papers published in a longer time span.
翻译:传统文献分析主要侧重于专题、作者、摘要、关键词、参考等文献元数据等文献元数据,很少注意论文的主要内容。在许多科学领域,如科学、计算、工程等,在这些领域出版的科学论文中涉及的方法和数据集含有重要信息,对于域际分析以及算法和数据集建议非常有用。在本文中,我们提出了一个名为MDER的新实体识别模型,能够有效地从科学论文的主要文本内容中提取方法和数据集。该模型利用规则嵌入并采用CNN和Bi-LSTM与自留机制的平行结构。我们评估了从计算机科学四个研究领域出版的论文(即NLP、CV、数据模型和AI)中构建的数据集拟议模型模型。我们提出的实验结果表明,我们的模式在所有四个领域都应用了良好的直线评估,并展示了跨区域学习和识别的优良学习能力。我们还利用CNNN和B-LSTM和B-LSTM与自留机制平行结构的平行结构结构,我们评估了从我们出版的论文的模型到不同模型的模型的可靠程度。我们还进行了良好的实验,从而在数据库中展示了我们数据库中展示了良好的业绩的模型,从而展示了我们整个数据质量的模型的模型的模型的模型,从而展示了我们获得了良好的实验。