
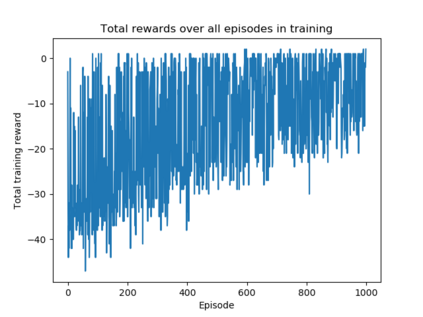
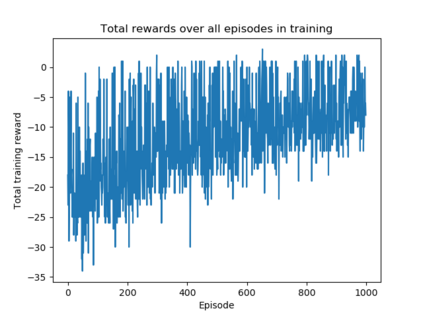
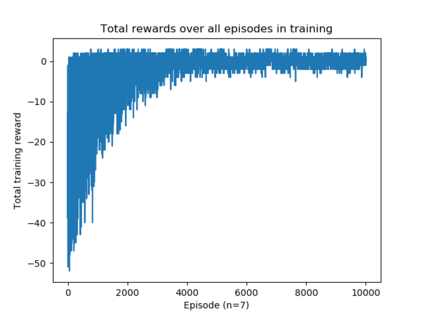
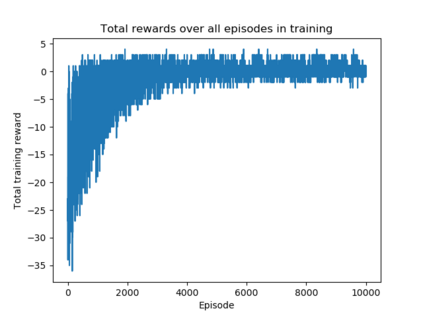
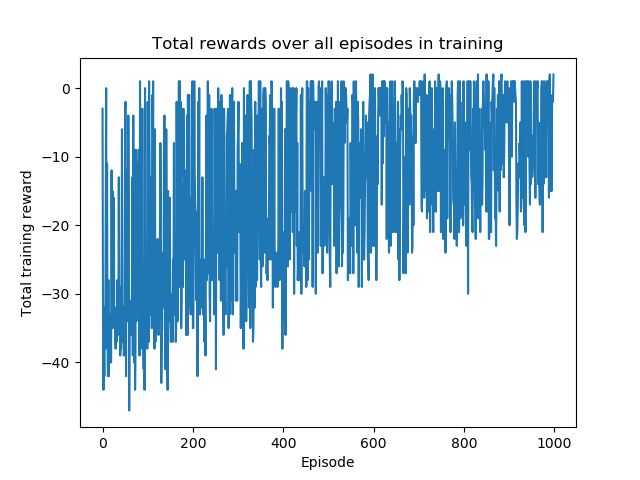
We use reinforcement learning to tackle the problem of untangling braids. We experiment with braids with 2 and 3 strands. Two competing players learn to tangle and untangle a braid. We interface the braid untangling problem with the OpenAI Gym environment, a widely used way of connecting agents to reinforcement learning problems. The results provide evidence that the more we train the system, the better the untangling player gets at untangling braids. At the same time, our tangling player produces good examples of tangled braids.
翻译:我们用强化学习来解决编织的编织问题。 我们用两条和三条线来试验编织。 两个相互竞争的玩家学会缠绕和解开编织的编织。 我们把编织的编织问题和OpenAI Gym环境联系起来,这是将代理与强化学习问题联系起来的一种广泛使用的方法。 结果证明我们训练系统越多,编织的编织者越容易解编织。 与此同时,我们编织的玩家就产生了交织的编织问题的良好例子。
相关内容

Arxiv
1+阅读 · 2021年11月22日
Arxiv
0+阅读 · 2021年11月18日
Arxiv
0+阅读 · 2021年11月17日

相关VIP内容
相关资讯
相关论文
Arxiv
1+阅读 · 2021年11月22日
Arxiv
0+阅读 · 2021年11月18日
Arxiv
0+阅读 · 2021年11月17日