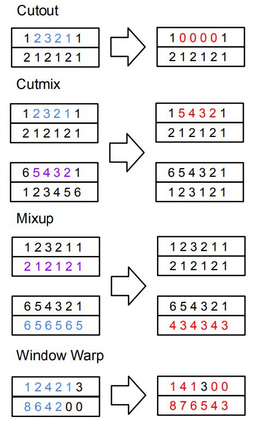
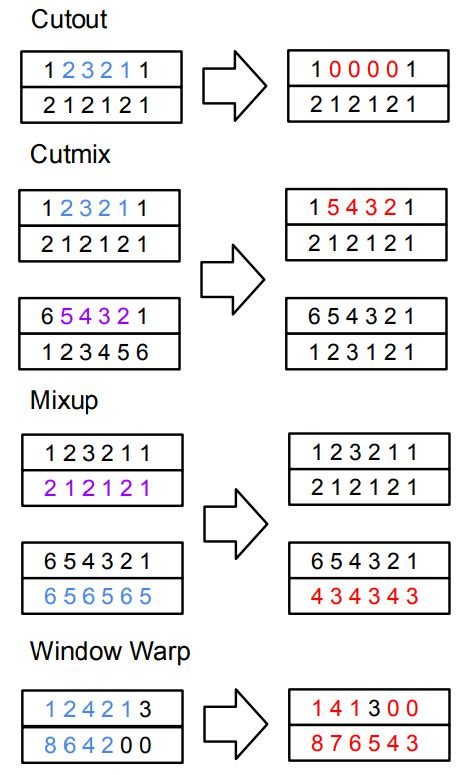
Neural networks are capable of learning powerful representations of data, but they are susceptible to overfitting due to the number of parameters. This is particularly challenging in the domain of time series classification, where datasets may contain fewer than 100 training examples. In this paper, we show that the simple methods of cutout, cutmix, mixup, and window warp improve the robustness and overall performance in a statistically significant way for convolutional, recurrent, and self-attention based architectures for time series classification. We evaluate these methods on 26 datasets from the University of East Anglia Multivariate Time Series Classification (UEA MTSC) archive and analyze how these methods perform on different types of time series data.. We show that the InceptionTime network with augmentation improves accuracy by 1% to 45% in 18 different datasets compared to without augmentation. We also show that augmentation improves accuracy for recurrent and self attention based architectures.
翻译:神经网络能够学习强大的数据表达方式,但由于参数数量众多,它们很容易被过度使用。这在时间序列分类领域特别具有挑战性,因为数据集可能包含不到100个培训实例。在本文中,我们显示,截断、切合、混和窗口扭曲的简单方法可以提高稳健性和总体性能,以具有统计意义的方式,为革命性、经常性和自我注意的基于时间序列的架构分类提供具有统计意义的数据。我们评估东安格丽雅大学多变时间序列分类(UEA MDC)档案中的26个数据集的这些方法,并分析这些方法在不同类型的时间序列数据上如何运行。我们显示,与不增强相比,扩增的InvitionTime网络在18个不同的数据集中提高了准确性1%至45%。我们还表明,扩增提高了经常性和自关注架构的准确性。