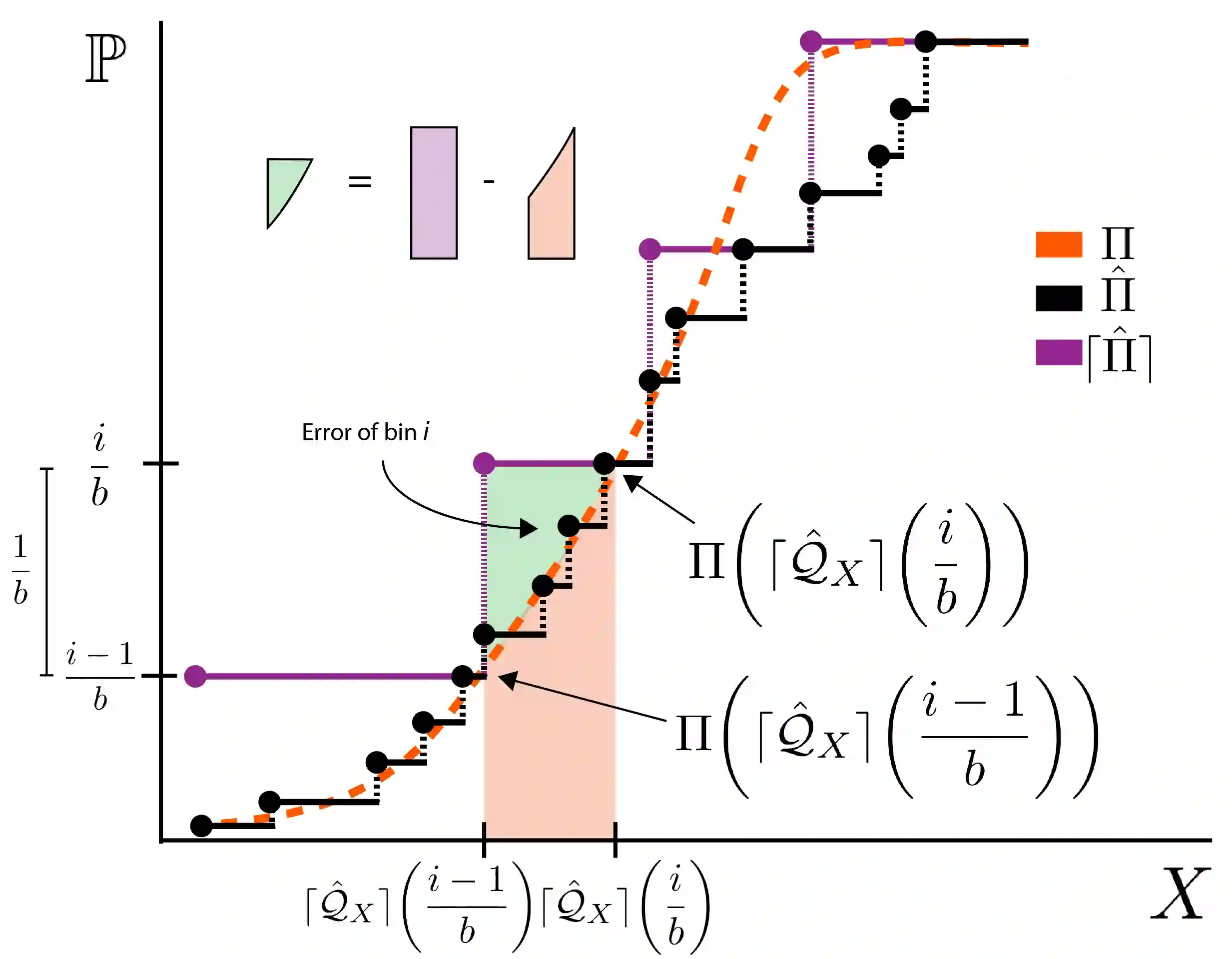
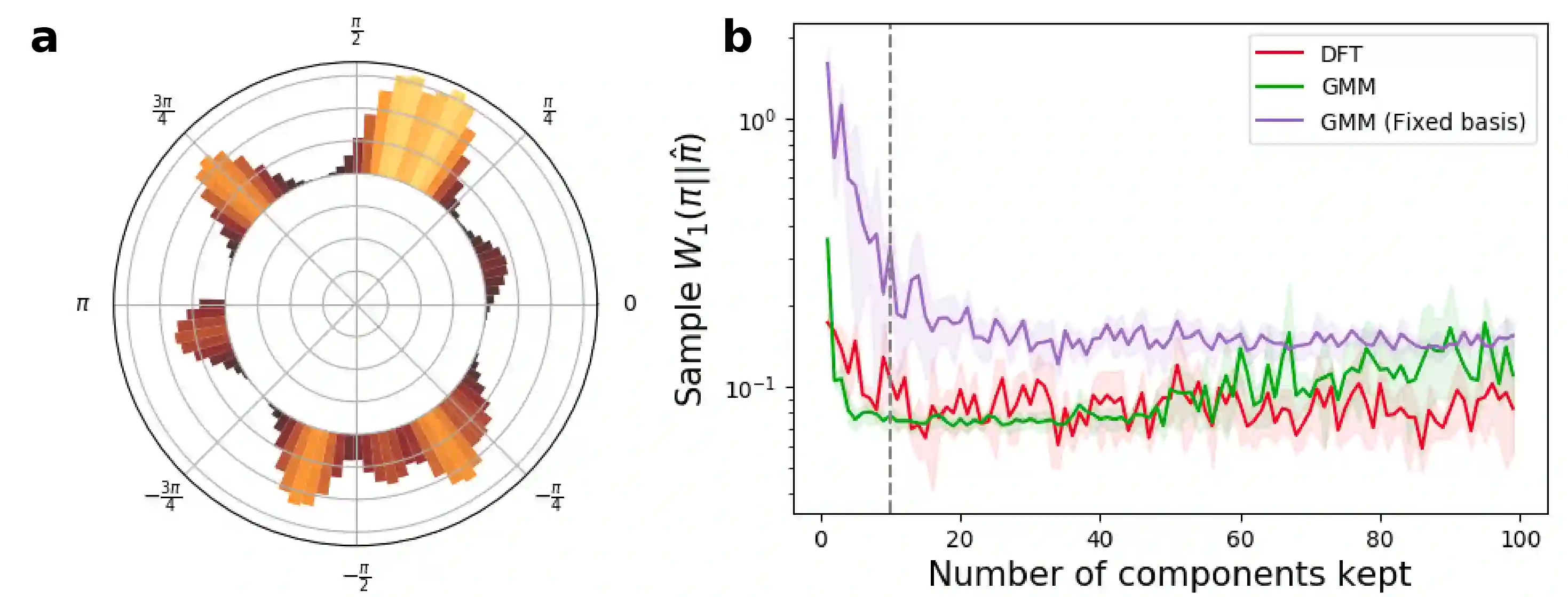
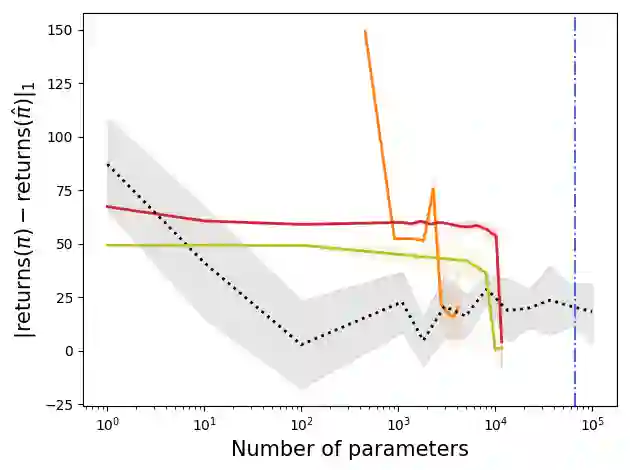
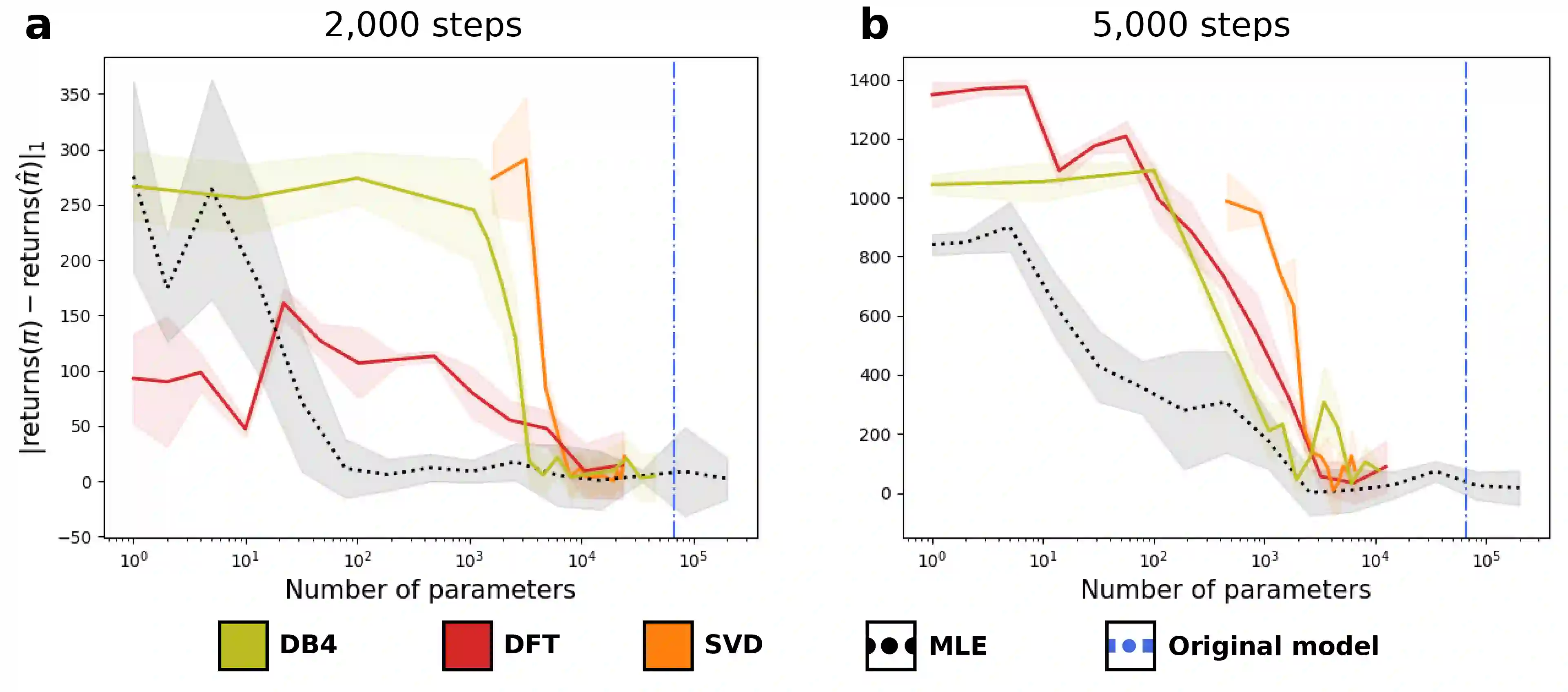
We propose a general framework for policy representation for reinforcement learning tasks. This framework involves finding a low-dimensional embedding of the policy on a reproducing kernel Hilbert space (RKHS). The usage of RKHS based methods allows us to derive strong theoretical guarantees on the expected return of the reconstructed policy. Such guarantees are typically lacking in black-box models, but are very desirable in tasks requiring stability. We conduct several experiments on classic RL domains. The results confirm that the policies can be robustly embedded in a low-dimensional space while the embedded policy incurs almost no decrease in return.
翻译:我们为强化学习任务提出了政策代表总框架。这个框架包括寻找一个低维的内核Hilbert空间再生政策(RKHS)嵌入。使用基于RKHS的方法使我们能够从理论上对重建后的政策的预期回报获得有力的保障。这种保障通常缺乏黑箱模式,但在需要稳定的任务中是非常可取的。我们在传统的RL领域进行若干实验。结果证实,政策可以牢固地嵌入一个低维空间,而嵌入的政策几乎没有回报下降。