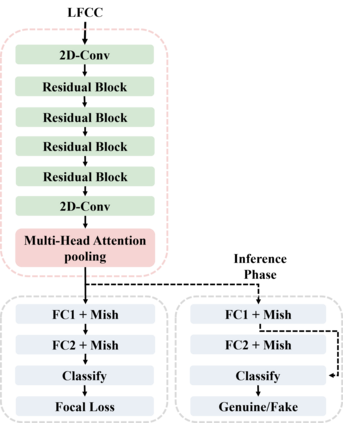
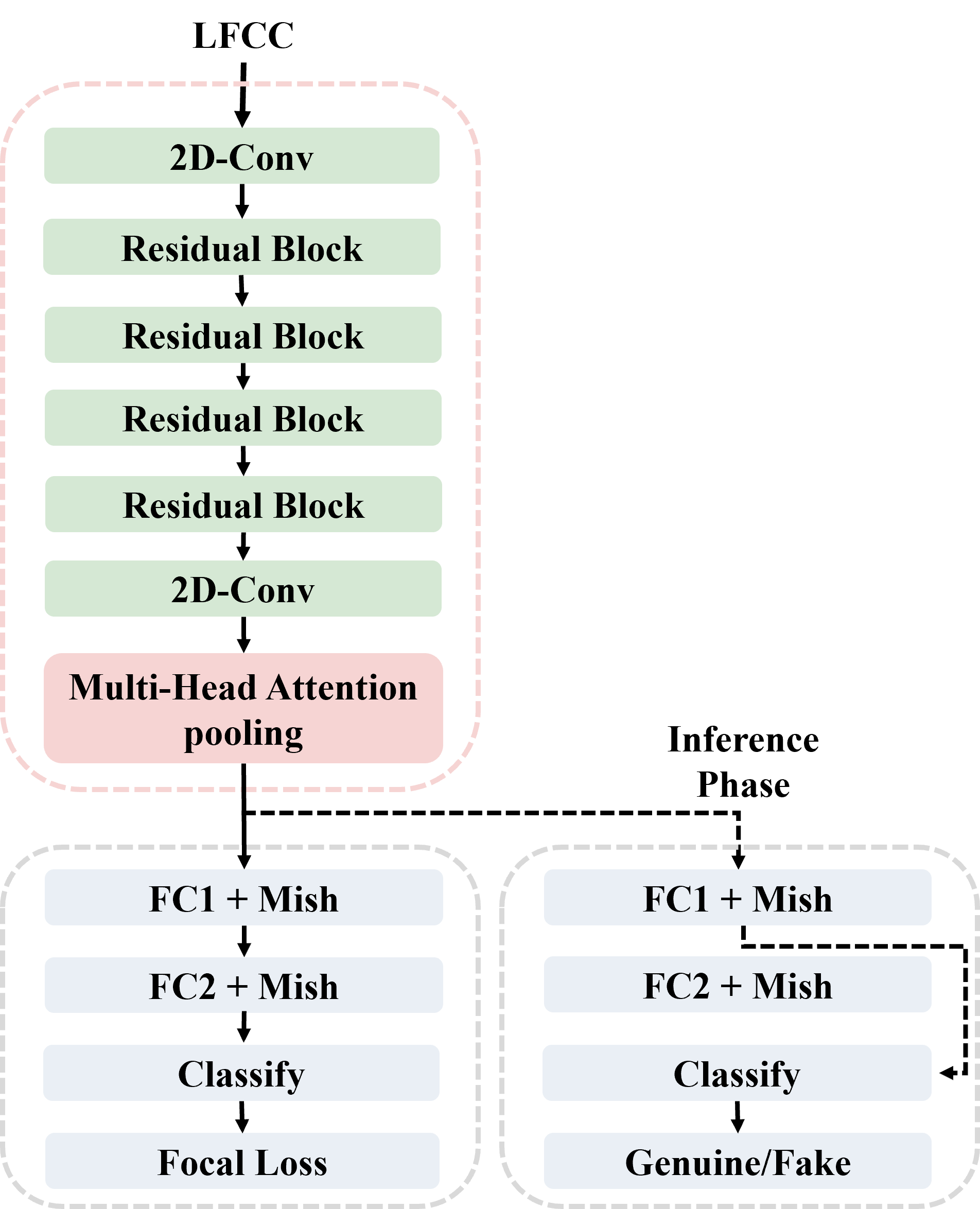
This paper describes our best system and methodology for ADD 2022: The First Audio Deep Synthesis Detection Challenge\cite{Yi2022ADD}. The very same system was used for both two rounds of evaluation in Track 3.2 with a similar training methodology. The first round of Track 3.2 data is generated from Text-to-Speech(TTS) or voice conversion (VC) algorithms, while the second round of data consists of generated fake audio from other participants in Track 3.1, aiming to spoof our systems. Our systems use a standard 34-layer ResNet, with multi-head attention pooling \cite{india2019self} to learn the discriminative embedding for fake audio and spoof detection. We further utilize neural stitching to boost the model's generalization capability in order to perform equally well in different tasks, and more details will be explained in the following sessions. The experiments show that our proposed method outperforms all other systems with a 10.1% equal error rate(EER) in Track 3.2.
翻译:本文介绍了我们用于ADD 2022 的最佳系统和方法:第一声深合成探测挑战(Yi2022AD) 。同一系统用于第3.2轨的两轮评价,采用了类似的培训方法。第一轮3.2轨数据来自文本到语音(TTS)或语音转换(VC)算法,而第二轮数据则来自第3.1轨中其他参与者生成的假音,目的是粉碎我们的系统。我们的系统使用标准34层ResNet,多层注意力集合\cite{india2019self}来学习模拟音波探测的歧视性嵌入。我们进一步利用神经缝合来增强模型的通用能力,以便在不同任务中同样出色地执行,并将在下几次会议上解释更多细节。实验显示,我们拟议的方法在3.2轨中以10.1%的误差率(ER)超过所有其他系统。