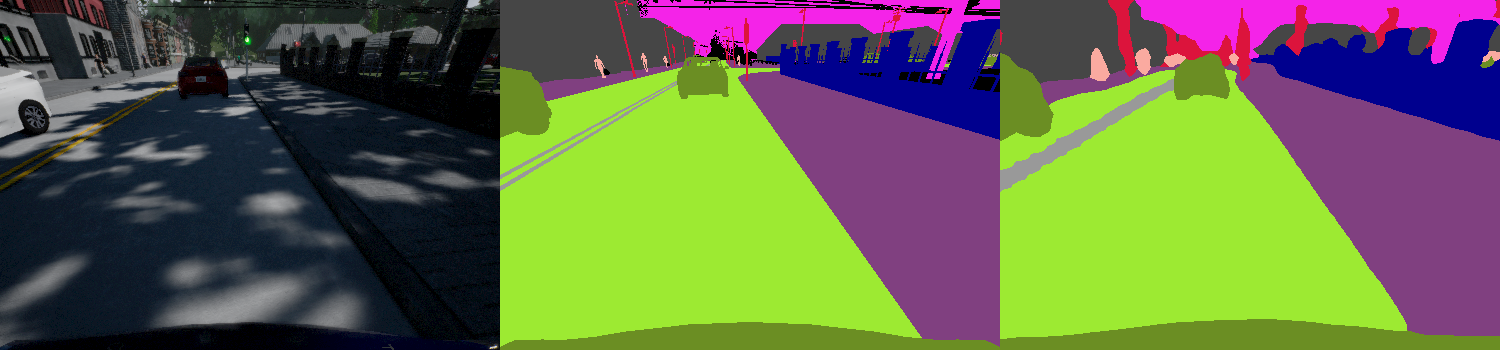
In this paper, we present a state-of-the-art reinforcement learning method for autonomous driving. Our approach employs temporal difference learning in a Bayesian framework to learn vehicle control signals from sensor data. The agent has access to images from a forward facing camera, which are preprocessed to generate semantic segmentation maps. We trained our system using both ground truth and estimated semantic segmentation input. Based on our observations from a large set of experiments, we conclude that training the system on ground truth input data leads to better performance than training the system on estimated input even if estimated input is used for evaluation. The system is trained and evaluated in a realistic simulated urban environment using the CARLA simulator. The simulator also contains a benchmark that allows for comparing to other systems and methods. The required training time of the system is shown to be lower and the performance on the benchmark superior to competing approaches.
翻译:在本文中,我们展示了一种最先进的自动驾驶强化学习方法。我们的方法在巴伊西亚框架中采用时间差异学习方法,从感应数据中学习车辆控制信号。代理器可以访问前方摄影机的图像,这些图像被预先处理,以生成语义分解图。我们用地面真实和估计语义分解输入来培训我们的系统。根据我们从大量实验中得出的观测结果,我们的结论是,在地面对系统进行真相输入数据培训比对系统进行关于估计输入的系统培训效果更好,即使估计输入用于评估。该系统在现实的模拟城市环境中使用CARLA模拟器进行训练和评价。模拟器还载有一个基准,以便与其他系统和方法进行比较。该系统所需的培训时间要低一些,基准比竞争方法要好。