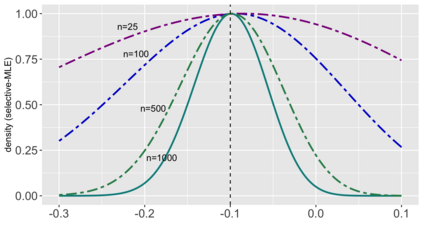
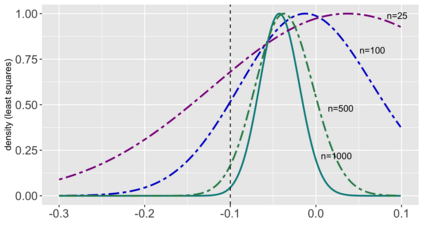
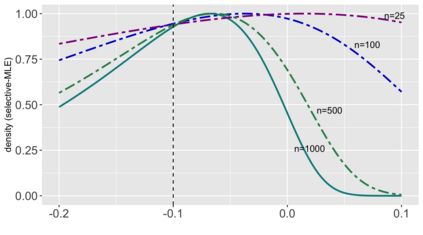
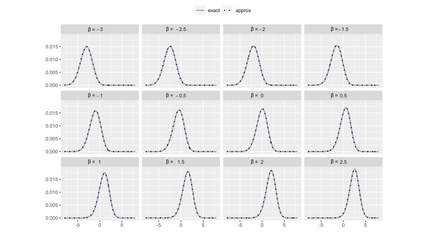
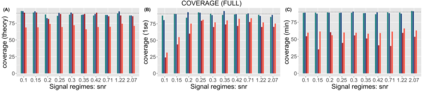
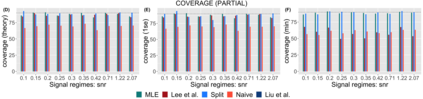
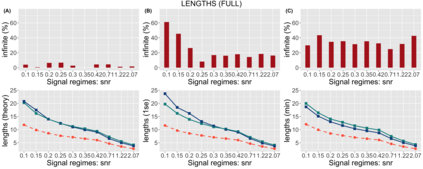
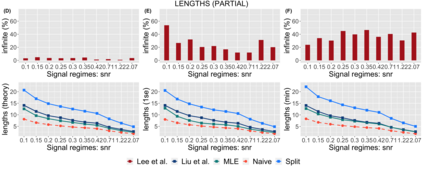
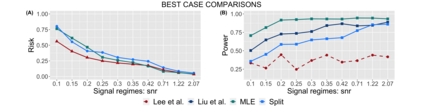
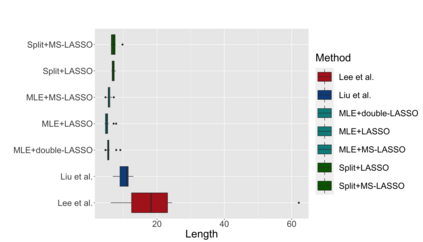
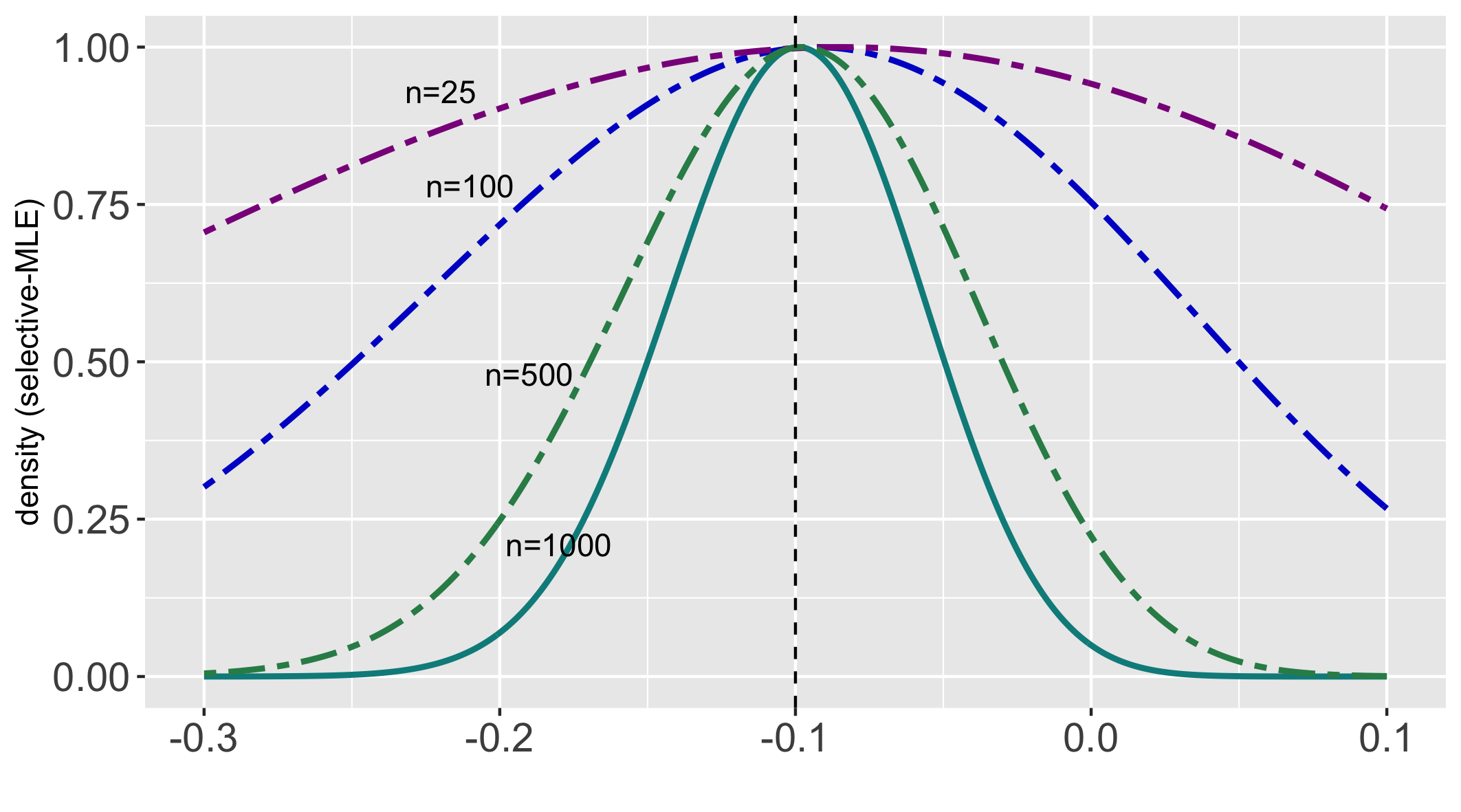
Several strategies have been developed recently to ensure valid inference after model selection; some of these are easy to compute, while others fare better in terms of inferential power. In this paper, we consider a selective inference framework for Gaussian data. We propose a new method for inference through approximate maximum likelihood estimation. Our goal is to: (i) achieve better inferential power with the aid of randomization, (ii) bypass expensive MCMC sampling from exact conditional distributions that are hard to evaluate in closed forms. We construct approximate inference, for e.g. p-values, confidence intervals etc., by solving a fairly simple, convex optimization problem. We illustrate the potential of our method across wide-ranging values of signal-to-noise ratio in simulations. On a cancer gene expression data set we find that our method improves upon the inferential power of some commonly used strategies for selective inference.
翻译:最近制定了若干战略,以确保在模型选择后进行有效推断;其中一些比较容易计算,而另一些则比较容易计算,在推论能力方面比较好。在本文中,我们考虑高斯数据有选择性推论框架。我们提出一种新的方法,通过估计最大可能性来进行推论。我们的目标是:(一) 在随机化的帮助下,获得更好的推论能力;(二) 绕过难以以封闭形式评估的精确条件分布的昂贵的MCMC取样。我们通过解决一个非常简单、共性优化的问题,构建了近似推论,例如p-value、信任间隔等。我们展示了我们的方法在模拟中在信号对噪音比率的广泛价值方面的潜力。关于癌症基因表达数据集,我们发现我们的方法改进了某些常用的选择性推论策略的推论能力。