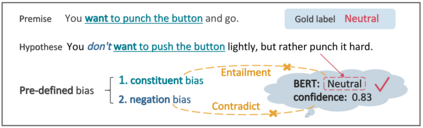
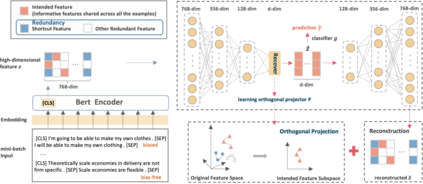
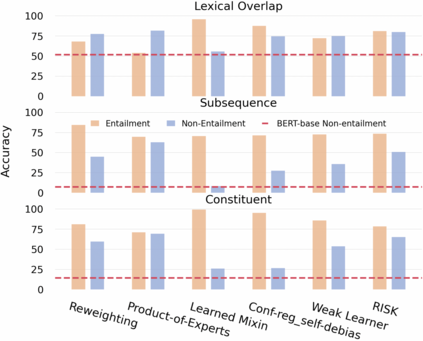
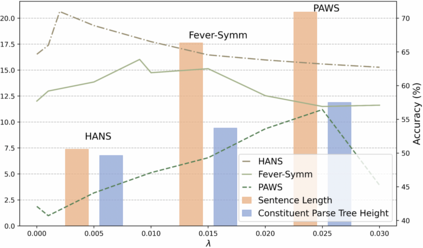
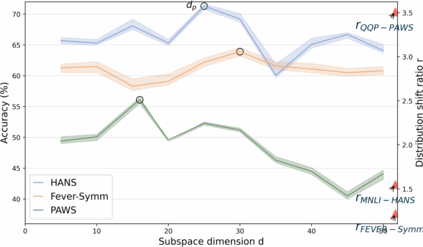
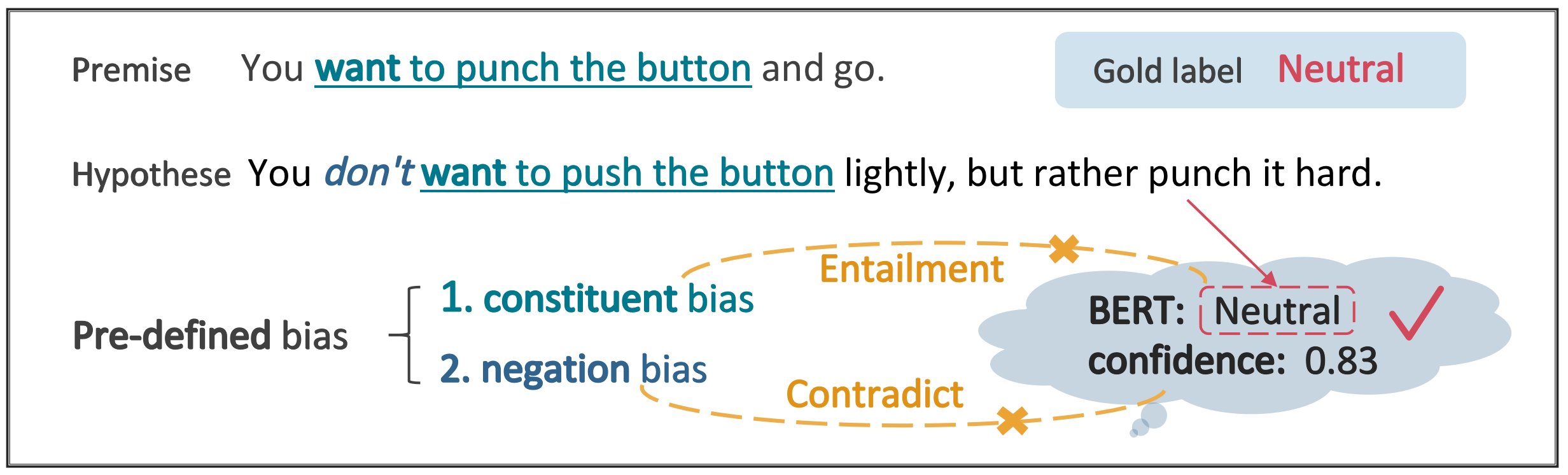
Datasets with significant proportions of bias present threats for training a trustworthy model on NLU tasks. Despite yielding great progress, current debiasing methods impose excessive reliance on the knowledge of bias attributes. Definition of the attributes, however, is elusive and varies across different datasets. Furthermore, leveraging these attributes at input level to bias mitigation may leave a gap between intrinsic properties and the underlying decision rule. To narrow down this gap and liberate the supervision on bias, we suggest extending bias mitigation into feature space. Therefore, a novel model, Recovering Intended-Feature Subspace with Knowledge-Free (RISK) is developed. Assuming that shortcut features caused by various biases are unintended for prediction, RISK views them as redundant features. When delving into a lower manifold to remove redundancies, RISK reveals that an extremely low-dimensional subspace with intended features can robustly represent the highly biased dataset. Empirical results demonstrate our model can consistently improve model generalization to out-of-distribution set, and achieves a new state-of-the-art performance.
翻译:尽管取得了巨大进展,但目前的贬低方法却过分依赖偏见属性的知识。但是,属性的定义是难以捉摸的,而且在不同数据集之间也各不相同。此外,在投入层面利用这些属性来减少偏见,可能会在内在属性和基本决策规则之间留下差距。为了缩小这一差距并放松对偏见的监督,我们建议将偏见的缓解扩大到特征空间。因此,开发了一个新颖的模型,即重新利用无知识的内在亚空间(RISK)。假设各种偏差造成的捷径特征对于预测来说是无意的,RISK认为它们是多余的特征。在进入一个较低的多功能来消除冗余时,RISK显示,一个具有预期特征的极低维度的子空间可以有力地代表高度偏差的数据集。根据经验,我们的模式可以不断改进模型的概括性,以超出分布范围,并实现新的状态性业绩。