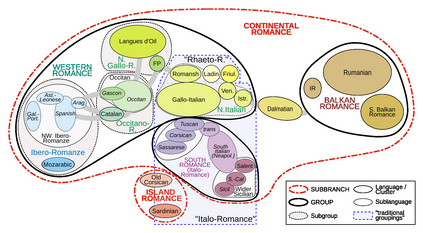
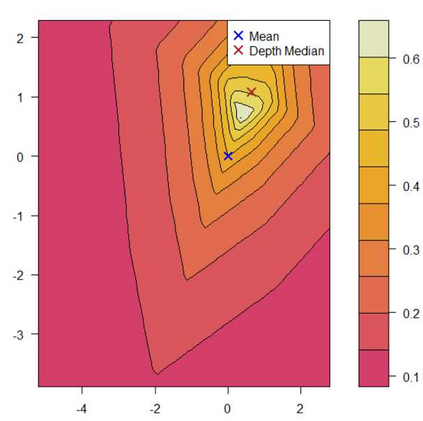
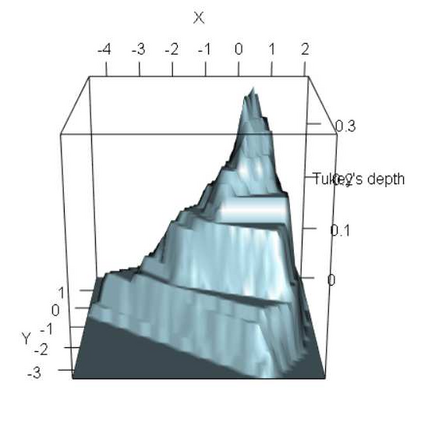
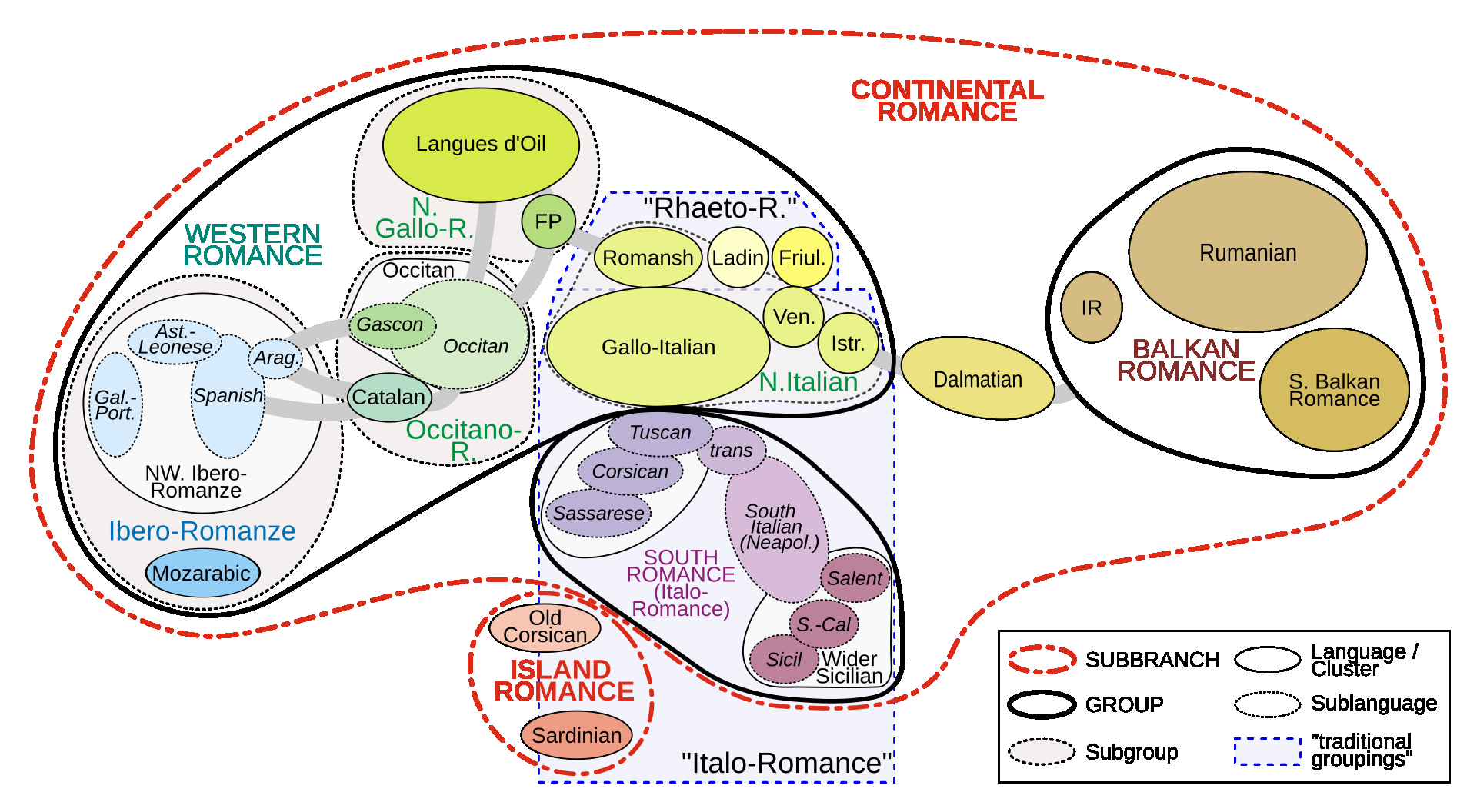
Any approach aimed at pasteurizing and quantifying a particular phenomenon must include the use of robust statistical methodologies for data analysis. With this in mind, the purpose of this study is to present statistical approaches that may be employed in nonparametric nonhomogeneous data frameworks, as well as to examine their application in the field of natural language processing and language clustering. Furthermore, this paper discusses the many uses of nonparametric approaches in linguistic data mining and processing. The data depth idea allows for the centre-outward ordering of points in any dimension, resulting in a new nonparametric multivariate statistical analysis that does not require any distributional assumptions. The concept of hierarchy is used in historical language categorisation and structuring, and it aims to organise and cluster languages into subfamilies using the same premise. In this regard, the current study presents a novel approach to language family structuring based on non-parametric approaches produced from a typological structure of words in various languages, which is then converted into a Cartesian framework using MDS. This statistical-depth-based architecture allows for the use of data-depth-based methodologies for robust outlier detection, which is extremely useful in understanding the categorization of diverse borderline languages and allows for the re-evaluation of existing classification systems. Other depth-based approaches are also applied to processes such as unsupervised and supervised clustering. This paper therefore provides an overview of procedures that can be applied to nonhomogeneous language classification systems in a nonparametric framework.
翻译:任何旨在消化和量化特定现象的方法都必须包括使用稳健的统计方法进行数据分析。考虑到这一点,本研究的目的是提出可用于非对称非多元性数据框架的统计方法,并审查这些方法在自然语言处理和语言群集领域的应用情况。此外,本文件讨论了语言数据挖掘和处理中多种非对称方法的多种用途。数据深度理念允许在任何层面对点进行中外排序,从而产生一个新的非对称多变量统计分析,不需要任何分布性假设。在历史语言分类和结构中使用等级概念,目的是利用同一前提将语言组织起来并分组成次家庭。在这方面,本研究提出了一种新颖的方法,用于语言家庭在语言的分类和处理中采用非参数性方法,然后用MDS转换成碳tes框架。这种基于统计的架构允许使用非基于数据的深度分类和结构来使用非基于数据的深度方法进行分类和结构结构的分类,从而能够将这种非基于数据的分类方法组织起来进行分类,从而能够对基于不同语言的分类程序进行严格的分类。在目前采用的分类中,对基于纸质的分类进行其他的分类的分类进行有用的再评估,也是一种非常有用的方法。