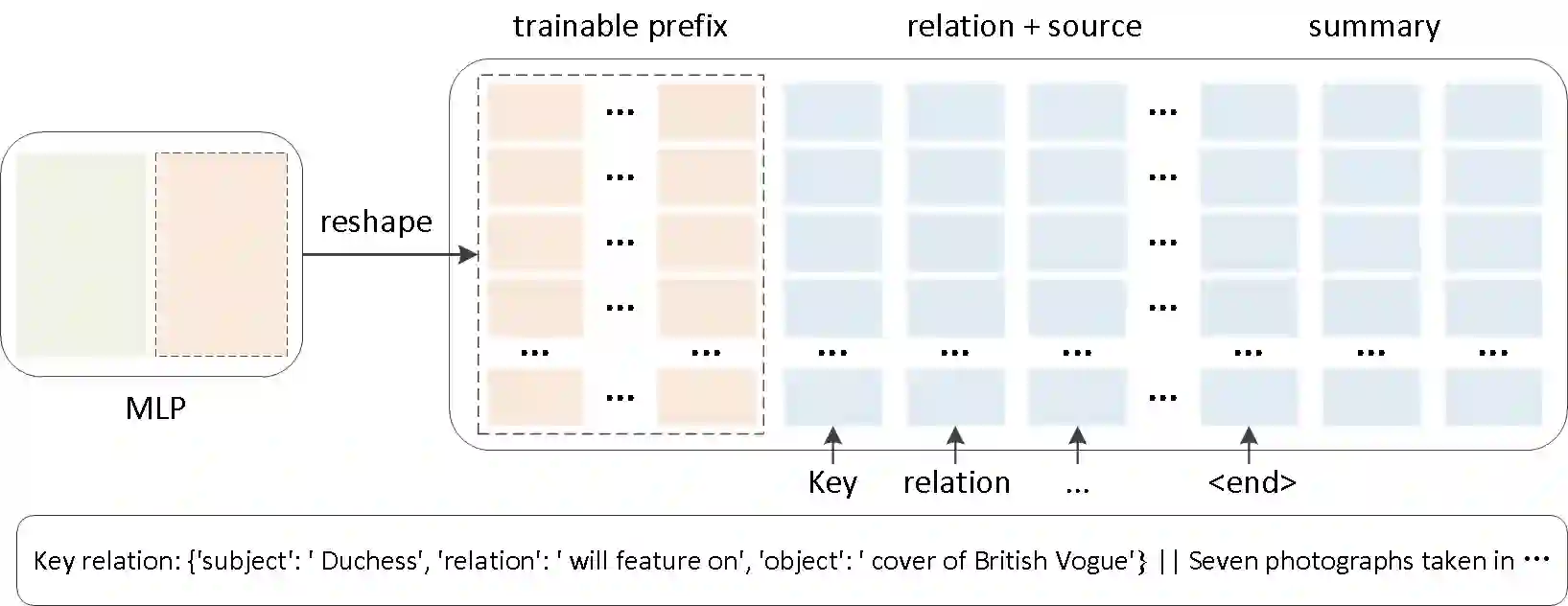
Despite the great development of document summarization techniques nowadays, factual inconsistencies between the generated summaries and the original text still occur from time to time. This paper proposes a prefix-tuning-based approach that uses a set of trainable continuous prefix prompt together with discrete prompts to aid model generation, which makes a significant impact on both CNN/Daily Mail and XSum summaries generated using GPT-2. The improvements on fact preservation in the generated summaries indicates the effectiveness of adopting this prefix-tuning-based method in knowledge-enhanced document summarization, and also shows a great potential on other natural language processing tasks.
翻译:尽管目前文件汇总技术有了很大发展,但制作的摘要与原始文本之间事实上的不一致情况不时发生,本文件建议采用前缀调整办法,采用一套可训练的连续连续前缀,同时采用独立的提示,帮助模型生成,对使用GPT-2制作的有线电视新闻网/Daily Mail和XSum摘要都产生重大影响。 所制作的摘要中关于事实保存的改进表明在知识强化的文件汇总中采用这种前缀调整方法的有效性,并显示出对其他自然语言处理任务的巨大潜力。