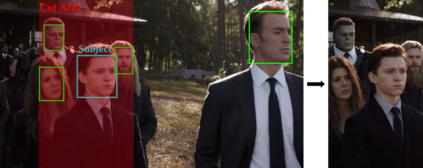
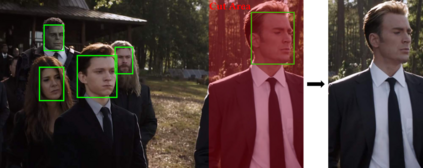
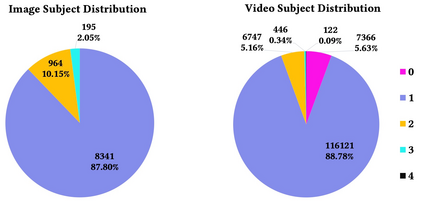
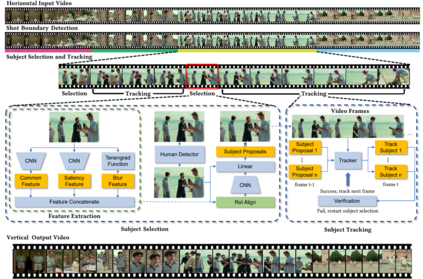
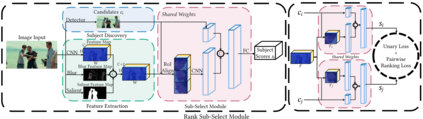
Alongside the prevalence of mobile videos, the general public leans towards consuming vertical videos on hand-held devices. To revitalize the exposure of horizontal contents, we hereby set forth the exploration of automated horizontal-to-vertical (abbreviated as H2V) video conversion with our proposed H2V framework, accompanied by an accurately annotated H2V-142K dataset. Concretely, H2V framework integrates video shot boundary detection, subject selection and multi-object tracking to facilitate the subject-preserving conversion, wherein the key is subject selection. To achieve so, we propose a Rank-SS module that detects human objects, then selects the subject-to-preserve via exploiting location, appearance, and salient cues. Afterward, the framework automatically crops the video around the subject to produce vertical contents from horizontal sources. To build and evaluate our H2V framework, H2V-142K dataset is densely annotated with subject bounding boxes for 125 videos with 132K frames and 9,500 video covers, upon which we demonstrate superior subject selection performance comparing to traditional salient approaches, and exhibit promising horizontal-to-vertical conversion performance overall. By publicizing this dataset as well as our approach, we wish to pave the way for more valuable endeavors on the horizontal-to-vertical video conversion task.
翻译:在移动视频盛行的同时,普通公众倾向于在手持设备上消费垂直视频。为了振兴横向内容的曝光,我们特此提出探索与我们提议的H2V框架一起自动横向向纵向(以H2V为缓冲)视频转换,并配有一个准确的注解H2V-142K数据集。具体地说,H2V框架将视频拍摄边界探测、主题选择和多点跟踪结合起来,以便利主题保留转换,其中要选择钥匙。为了实现这一点,我们提议了一个等级SS模块,用于探测人类物体,然后通过利用位置、外观和突出提示选择主题到保护对象。之后,框架自动将主题周围的视频从横向源产生垂直内容。为了建立和评估我们的H2V框架,H2V-142K数据集具有密集的注解,同时配有125个带有132K框架和9 500视频封面的标注框,以此显示与传统突出方法相比的高级主题选择性表现,并展示有希望的横向向纵向转换总体表现的希望。随后,框架将围绕该主题自动将围绕该主题制作视频,作为我们高水平任务。