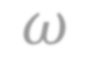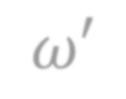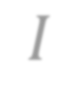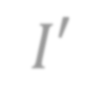In this paper, we study PAC learnability and certification of predictions under instance-targeted poisoning attacks, where the adversary who knows the test instance may change a fraction of the training set with the goal of fooling the learner at the test instance. Our first contribution is to formalize the problem in various settings and to explicitly model subtle aspects such as the proper or improper nature of the learning, learner's randomness, and whether (or not) adversary's attack can depend on it. Our main result shows that when the budget of the adversary scales sublinearly with the sample complexity, (improper) PAC learnability and certification are achievable; in contrast, when the adversary's budget grows linearly with the sample complexity, the adversary can potentially drive up the expected 0-1 loss to one. We also study distribution-specific PAC learning in the same attack model and show that proper learning with certification is possible for learning half spaces under natural distributions. Finally, we empirically study the robustness of K nearest neighbour, logistic regression, multi-layer perceptron, and convolutional neural network on real data sets against targeted-poisoning attacks. Our experimental results show that many models, especially state-of-the-art neural networks, are indeed vulnerable to these strong attacks. Interestingly, we observe that methods with high standard accuracy might be more vulnerable to instance-targeted poisoning attacks.
翻译:在本文中,我们研究了PAC在实验性中毒袭击中是否可学习和认证预测,在试验性袭击中,知道试验性袭击的对手可能会改变一部分培训内容,目的是在试验性袭击中愚弄学习者。我们的第一个贡献是在各种环境中将问题正规化,并明确模拟诸如学习的正确或不适当性质、学习者随机性,以及对手攻击是否(或不)取决于它等微妙方面。我们的主要结果显示,当对手规模的预算与抽样复杂性(不适当)PAC的可学习性和认证相匹配;相反,当对手的预算随着抽样复杂性的线性增长而可能改变部分培训内容时,对手的预算可能会把预期的0-1损失提高到1。我们还研究同一攻击模型中具体的分配性PAC学习,并表明,在自然分布下学习半空间时,可以进行适当的认证学习。最后,我们从经验上研究了K近邻、物流回归、多层次感官和进化神经网络在真实数据组合中与目标性袭击相对的精确性袭击之间的强度;我们实验性结果显示,这些高度模型确实可以观测到目标性攻击。我们这些高度攻击的精确性模型。我们这些实验性模型能够观测到更精确性攻击。