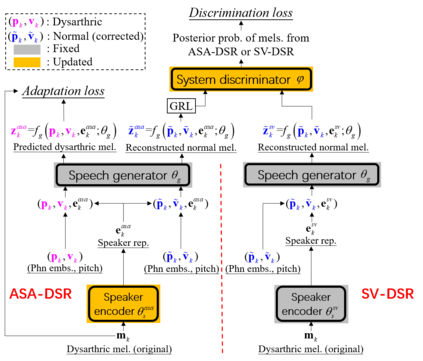
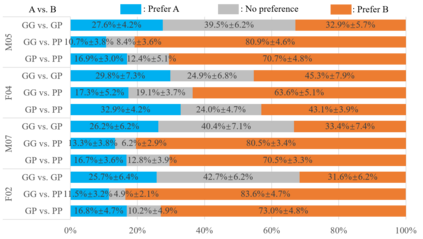
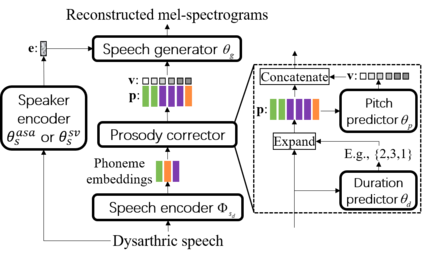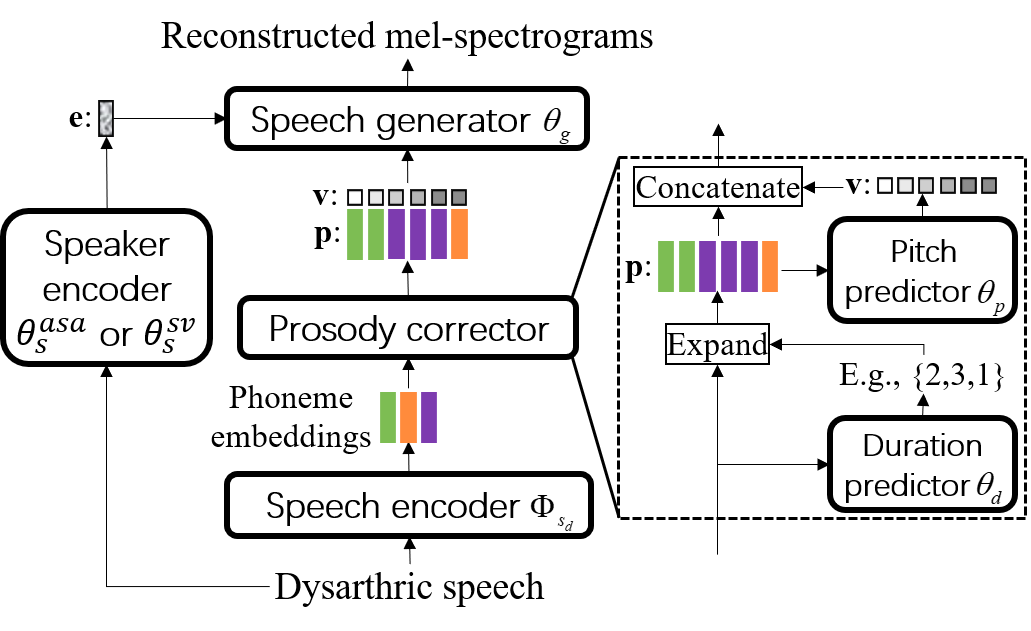Dysarthric speech reconstruction (DSR), which aims to improve the quality of dysarthric speech, remains a challenge, not only because we need to restore the speech to be normal, but also must preserve the speaker's identity. The speaker representation extracted by the speaker encoder (SE) optimized for speaker verification has been explored to control the speaker identity. However, the SE may not be able to fully capture the characteristics of dysarthric speakers that are previously unseen. To address this research problem, we propose a novel multi-task learning strategy, i.e., adversarial speaker adaptation (ASA). The primary task of ASA fine-tunes the SE with the speech of the target dysarthric speaker to effectively capture identity-related information, and the secondary task applies adversarial training to avoid the incorporation of abnormal speaking patterns into the reconstructed speech, by regularizing the distribution of reconstructed speech to be close to that of reference speech with high quality. Experiments show that the proposed approach can achieve enhanced speaker similarity and comparable speech naturalness with a strong baseline approach. Compared with dysarthric speech, the reconstructed speech achieves 22.3% and 31.5% absolute word error rate reduction for speakers with moderate and moderate-severe dysarthria respectively. Our demo page is released here: https://wendison.github.io/ASA-DSR-demo/
翻译:旨在改进反沙发言论质量的Dysarthric 语音重建(DSR)仍然是一项挑战,这不仅是因为我们需要恢复发言的正常,而且必须保持发言者的身份。已经探索了由发言者编码器(SE)为发言者核实而优化的发言者代表所抽取的发言者代表,以控制发言者的身份。然而,SE可能无法充分捕捉以前不为人知的有争议演讲者的特点。为了解决这一研究问题,我们提议了一个新的多任务学习战略,即对抗性演讲者适应(ASA),这不仅是因为我们需要使发言恢复正常,而且还必须保持发言者的身份特征。ASA的微调主要任务与目标表达器(SE)的演讲有效捕捉与身份有关的信息,而次要任务则是进行对抗性培训,以避免将不正常的演讲模式纳入经改造的演讲中,方法是使经重建的演讲的分发正规化,接近高质量的参考演讲。实验表明,拟议的方法可以使演讲者更加相似和可比的演讲自然性质,而采用强有力的基线方法。比D-dysharmical-laud Arent redual res redustrivation 和我们31%s redustrual 的演讲率分别为:real-de-rviolent 。