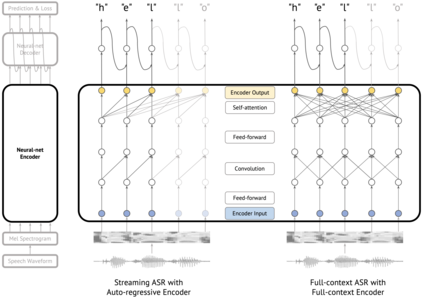
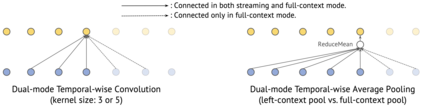
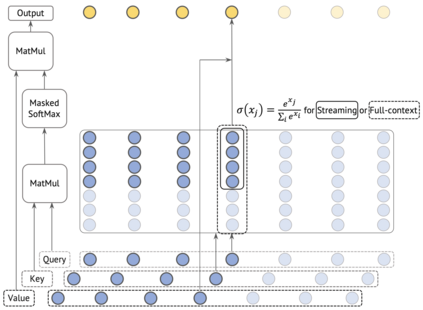
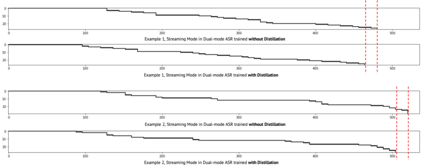
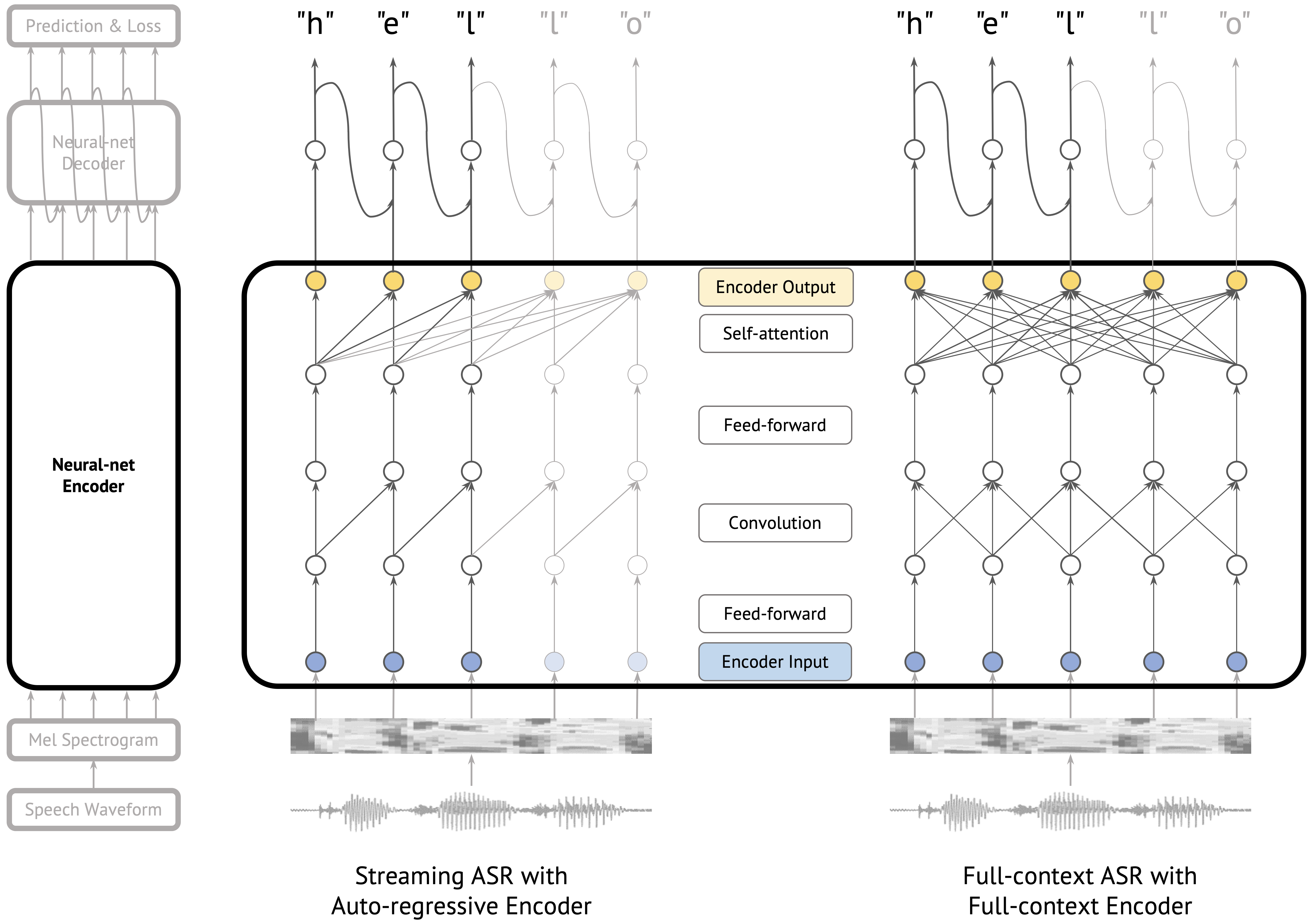
Streaming automatic speech recognition (ASR) aims to emit each hypothesized word as quickly and accurately as possible, while full-context ASR waits for the completion of a full speech utterance before emitting completed hypotheses. In this work, we propose a unified framework, Dual-mode ASR, to train a single end-to-end ASR model with shared weights for both streaming and full-context speech recognition. We show that the latency and accuracy of streaming ASR significantly benefit from weight sharing and joint training of full-context ASR, especially with inplace knowledge distillation during the training. The Dual-mode ASR framework can be applied to recent state-of-the-art convolution-based and transformer-based ASR networks. We present extensive experiments with two state-of-the-art ASR networks, ContextNet and Conformer, on two datasets, a widely used public dataset LibriSpeech and a large-scale dataset MultiDomain. Experiments and ablation studies demonstrate that Dual-mode ASR not only simplifies the workflow of training and deploying streaming and full-context ASR models, but also significantly improves both emission latency and recognition accuracy of streaming ASR. With Dual-mode ASR, we achieve new state-of-the-art streaming ASR results on both LibriSpeech and MultiDomain in terms of accuracy and latency.
翻译:在这项工作中,我们提议一个统一的框架,即双模版ASR,以训练一个单一端对端的ASR模型,其分量与分量共享,供流出和全文语音识别使用。我们显示,流出ASR的衬里和准确性从全文本ASR的权重共享和联合培训中大有裨益,特别是培训期间的知识蒸馏。双模版ASR框架可以适用于最近的艺术革命型和变异型ASR网络。我们介绍了两个数据集的广泛实验,一个广泛使用的公众数据集LibriSpeech和一个大型的LibriSpeech数据集,以及一个大型的多功能型数据集。实验和对比研究表明,Diremode ASR的分层精度精度,不仅在ASR的流流中,而且还在ASR的流流流流中大幅提升了ASR的精度,还大大改进了ASR的流流流中和流流中成果。