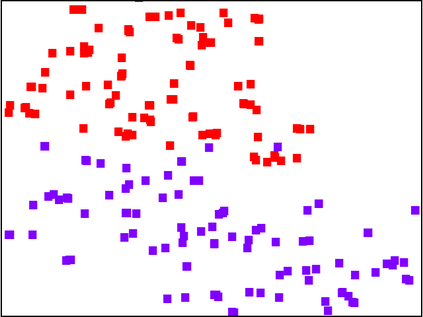
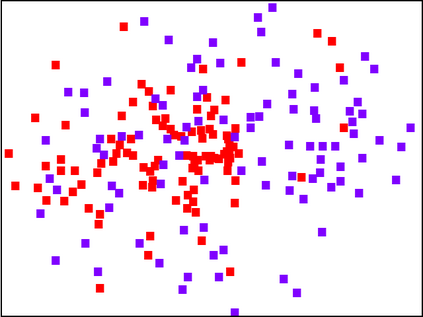
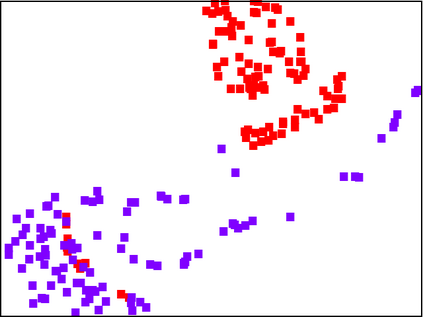
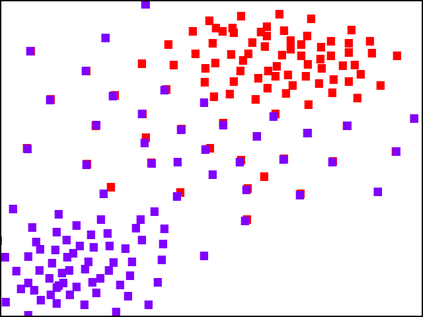
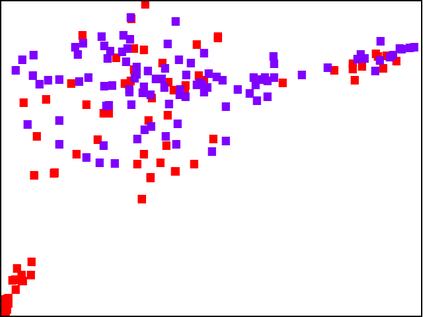
With the fast adoption of machine learning (ML) techniques, sharing of ML models is becoming popular. However, ML models are vulnerable to privacy attacks that leak information about the training data. In this work, we focus on a particular type of privacy attacks named property inference attack (PIA) which infers the sensitive properties of the training data through the access to the target ML model. In particular, we consider Graph Neural Networks (GNNs) as the target model, and distribution of particular groups of nodes and links in the training graph as the target property. While the existing work has investigated PIAs that target at graph-level properties, no prior works have studied the inference of node and link properties at group level yet. In this work, we perform the first systematic study of group property inference attacks (GPIA) against GNNs. First, we consider a taxonomy of threat models under both black-box and white-box settings with various types of adversary knowledge, and design six different attacks for these settings. We evaluate the effectiveness of these attacks through extensive experiments on three representative GNN models and three real-world graphs. Our results demonstrate the effectiveness of these attacks whose accuracy outperforms the baseline approaches. Second, we analyze the underlying factors that contribute to GPIA's success, and show that the target model trained on the graphs with or without the target property represents some dissimilarity in model parameters and/or model outputs, which enables the adversary to infer the existence of the property. Further, we design a set of defense mechanisms against the GPIA attacks, and demonstrate that these mechanisms can reduce attack accuracy effectively with small loss on GNN model accuracy.
翻译:随着机器学习技术的快速采用,共享ML模型正在变得普及。然而,ML模型很容易受到隐私攻击,而隐私攻击会泄露培训数据的信息。在这项工作中,我们侧重于一种特定类型的隐私攻击,其名称是财产推断攻击(PIA),通过访问目标ML模型来推断培训数据的敏感性质。特别是,我们认为图形神经网络(GNNS)是目标模型,在培训图中将特定节点和链接群体分布为目标财产。虽然现有工作已经调查了图层属性目标的PIA,但尚未研究节点的推论和链接。在这项工作中,我们侧重于一种特定类型的隐私攻击(PIA)的敏感性质。我们第一次系统研究通过访问目标MLML模型(GIA)来推断培训数据。首先,我们认为黑箱和白箱模型下威胁模型的分类是目标模型,为这些环境设计了六种不同的攻击。我们通过在三个具有代表性的GNNN模型上进行的广泛实验,而以前没有研究过将属性属性属性属性联系起来,在GPA的精确度上展示了这些基准参数的精确度方法。我们对这些攻击的精确性模型和第二个GA的结果展示了这些模型的精确度。我们对这些攻击的精确度的精确度的精确性能展示了。我们对这些攻击的精确性能展示了这些在GA的精确性能向GA的精确性能向GA的精确性向GA的精确性图。我们对这些攻击的精确度的精确度的精确性展示了。我们对GPA的结果。我们对这些攻击的精确性作了展示了这些精确性向的精确性能展示了。