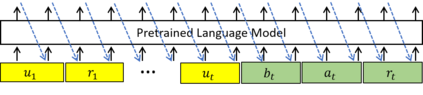
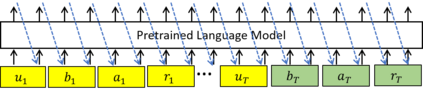
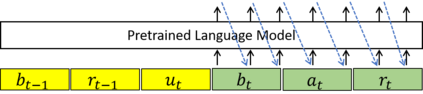
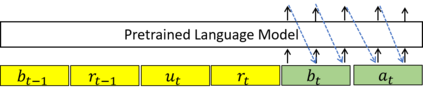
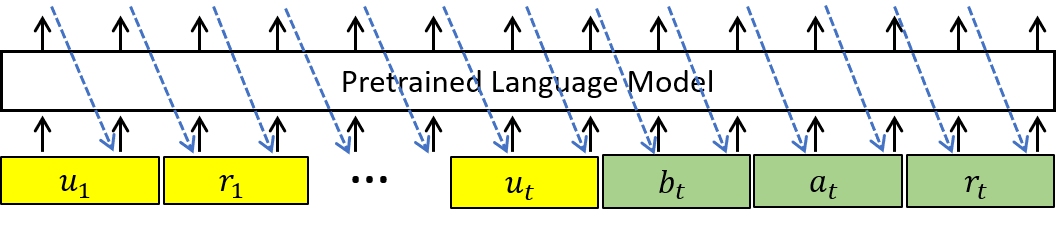
Recently, Transformer based pretrained language models (PLMs), such as GPT2 and T5, have been leveraged to build generative task-oriented dialog (TOD) systems. A drawback of existing PLM-based models is their non-Markovian architectures across turns, i.e., the whole history is used as the conditioning input at each turn, which brings inefficiencies in memory, computation and learning. In this paper, we propose to revisit Markovian Generative Architectures (MGA), which have been used in previous LSTM-based TOD systems, but not studied for PLM-based systems. Experiments on MultiWOZ2.1 show the efficiency advantages of the proposed Markovian PLM-based systems over their non-Markovian counterparts, in both supervised and semi-supervised settings.
翻译:最近,GPT2和T5等基于GPT2和T5等基于预先训练的变异语言模型(PLM)被利用来建立注重任务的对话(TOD)系统,现有基于PLM的模型的一个缺点是其非马尔科文结构的逆向性,即整个历史被用作每个转弯的调节投入,从而在记忆、计算和学习方面造成效率低下。在本文件中,我们提议重新审视以前基于LSTM的TOD系统使用的Markovian Genement 架构(MGA ), 但这些架构曾用于基于LSTM的TOD系统,但没有为基于PLM的系统进行研究。 关于多WOZ2.1的实验显示,拟议的Markovian PLM系统在监管和半监督环境下对非Markovian对应系统的效率优势。