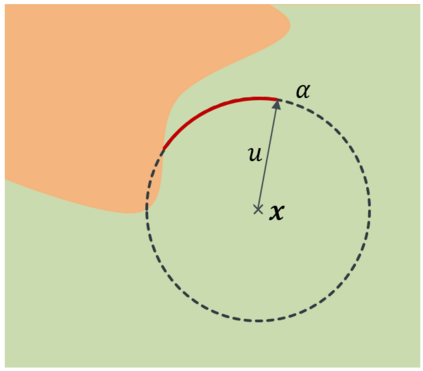
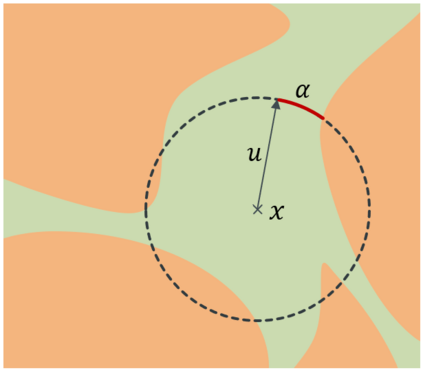
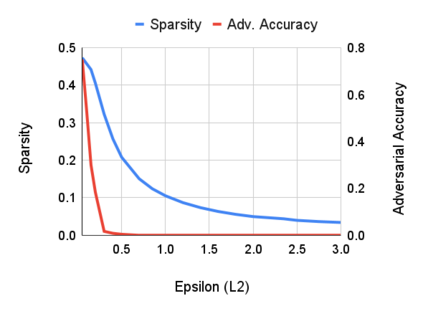
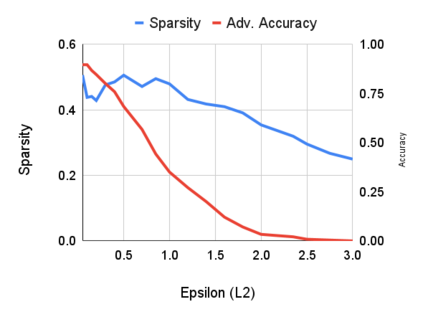
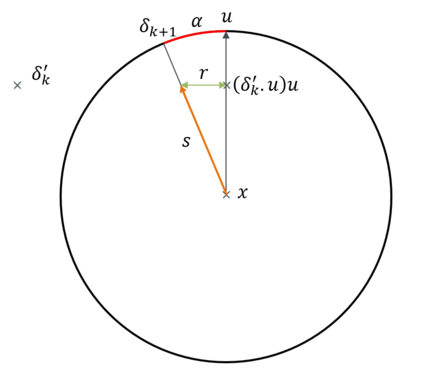
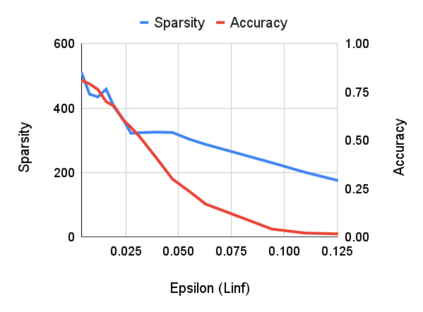
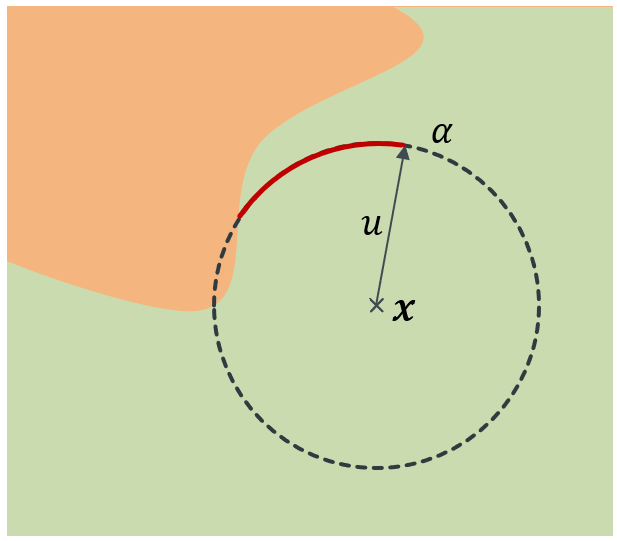
Robustness to adversarial attack is typically evaluated with adversarial accuracy. This metric quantifies the number of points for which, given a threat model, successful adversarial perturbations cannot be found. While essential, this metric does not capture all aspects of robustness and in particular leaves out the question of how many perturbations can be found for each point. In this work we introduce an alternative approach, adversarial sparsity, which quantifies how difficult it is to find a successful perturbation given both an input point and a constraint on the direction of the perturbation. This constraint may be angular (L2 perturbations), or based on the number of pixels (Linf perturbations). We show that sparsity provides valuable insight on neural networks in multiple ways. analyzing the sparsity of existing robust models illustrates important differences between them that accuracy analysis does not, and suggests approaches for improving their robustness. When applying broken defenses effective against weak attacks but not strong ones, sparsity can discriminate between the totally ineffective and the partially effective defenses. Finally, with sparsity we can measure increases in robustness that do not affect accuracy: we show for example that data augmentation can by itself increase adversarial robustness, without using adversarial training.
翻译:对抗性攻击的强力通常会以对抗性攻击的准确性来评估。 该量度测量了在威胁模式下无法找到成功的对抗性扰动的点数。 虽然该量度不能反映强力的所有方面, 特别是没有考虑到每个点可以找到多少扰动的问题。 在这项工作中, 我们引入了一种替代方法, 对抗性攻击的强力, 它量化了在输入点和对扰动方向的制约下找到成功干扰的难度。 这种制约可以是角的( L2 扰动), 或基于像素的数量( 利夫扰动) 。 我们表明, 强力性能提供了对神经网络的有价值的洞察力。 分析现有强力模型的广度表明它们之间的重要差异, 准确性分析没有效果, 并提出了改进它们坚固性的方法。 在对弱性攻击有效但非强力的防力下, 扰动性可以区分完全无效性和部分有效防御。 这种制约可以是角( L2 扰动性), 或以像等数为基础 。 我们表明, 强性能性能性能性能性能性能 能够测量性地测量我们用不强性地测量性 。 我们用强力性地测量性 。