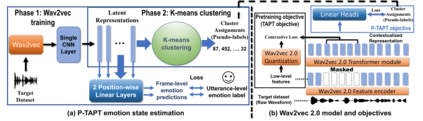
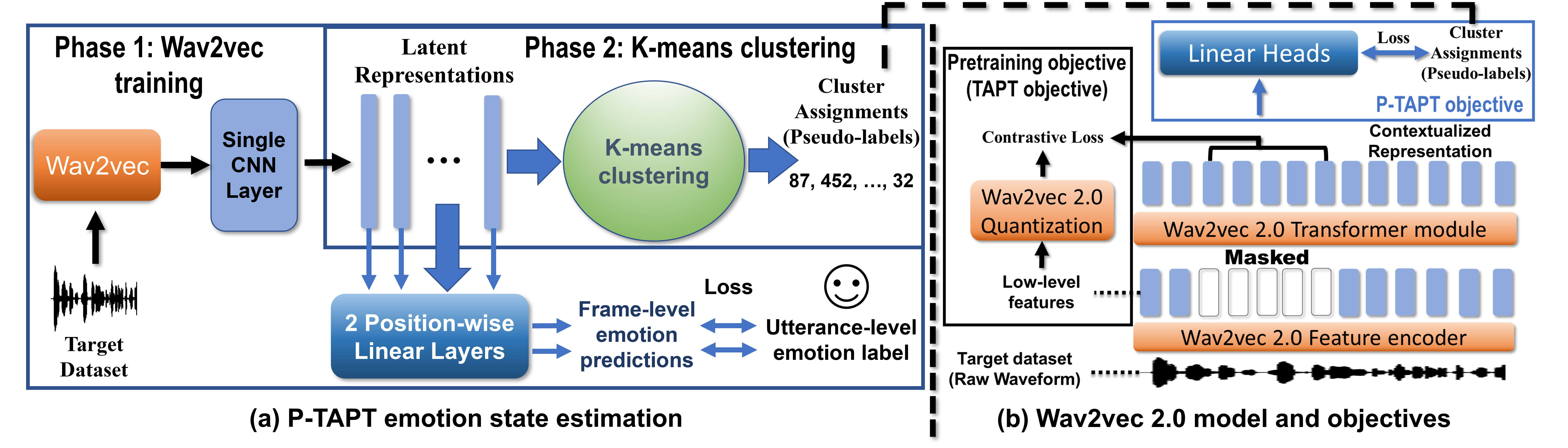
While Wav2Vec 2.0 has been proposed for speech recognition (ASR), it can also be used for speech emotion recognition (SER); its performance can be significantly improved using different fine-tuning strategies. Two baseline methods, vanilla fine-tuning (V-FT) and task adaptive pretraining (TAPT) are first presented. We show that V-FT is able to outperform state-of-the-art models on the IEMOCAP dataset. TAPT, an existing NLP fine-tuning strategy, further improves the performance on SER. We also introduce a novel fine-tuning method termed P-TAPT, which modifies the TAPT objective to learn contextualized emotion representations. Experiments show that P-TAPT performs better than TAPT, especially under low-resource settings. Compared to prior works in this literature, our top-line system achieved a 7.4\% absolute improvement in unweighted accuracy (UA) over the state-of-the-art performance on IEMOCAP. Our code is publicly available.
翻译:虽然提出了语音识别(ASR)Wav2Vec 2.0, 但也可用于语音情绪识别(SER);其性能可以通过不同的微调战略得到显著改善。首先介绍了两种基线方法,即香草微调(V-FT)和任务适应前训练(TAPT)。我们表明,V-FT能够超越IEMOCAP数据集的先进模型。TAPT是现行的NLP微调战略,它进一步提高了SER的性能。我们还引入了一种新型微调方法,称为P-TAPT,它改变了TAPT的目标以学习背景化情感表现。实验显示,P-TAPT的表现优于TT,特别是在低资源环境下。与以前在文献中开展的工作相比,我们的上线系统在IEMOCAP的无重量精确度方面实现了7.4 ⁇ 绝对改进。我们的代码是公开的。