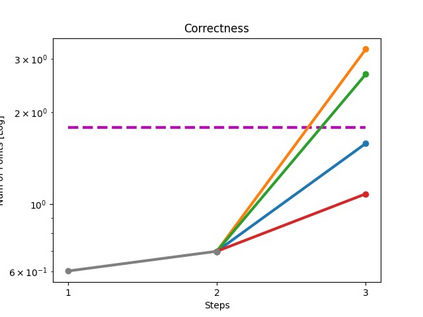
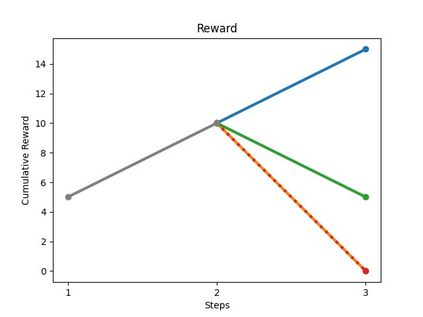
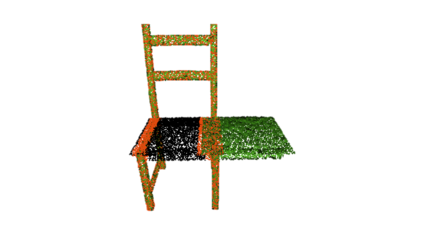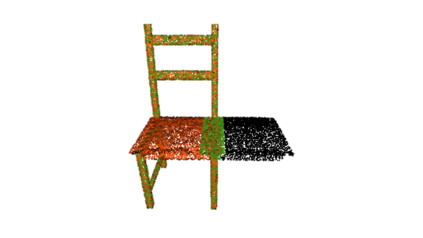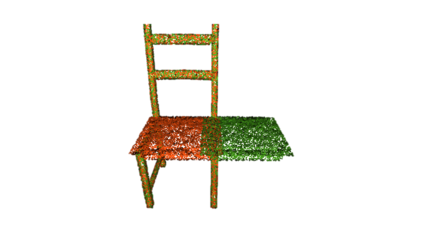The rise of simulation environments has enabled learning-based approaches for assembly planning, which is otherwise a labor-intensive and daunting task. Assembling furniture is especially interesting since furniture are intricate and pose challenges for learning-based approaches. Surprisingly, humans can solve furniture assembly mostly given a 2D snapshot of the assembled product. Although recent years have witnessed promising learning-based approaches for furniture assembly, they assume the availability of correct connection labels for each assembly step, which are expensive to obtain in practice. In this paper, we alleviate this assumption and aim to solve furniture assembly with as little human expertise and supervision as possible. To be specific, we assume the availability of the assembled point cloud, and comparing the point cloud of the current assembly and the point cloud of the target product, obtain a novel reward signal based on two measures: Incorrectness and incompleteness. We show that our novel reward signal can train a deep network to successfully assemble different types of furniture. Code and networks available here: https://github.com/METU-KALFA/AssembleRL
翻译:模拟环境的兴起使人们得以对组装规划采取基于学习的方法,这在其他方面是一项劳动密集型和艰巨的任务。组装家具特别令人感兴趣,因为家具错综复杂,对以学习为基础的方法构成挑战。令人惊讶的是,人类能够解决家具组装,主要是对组装产品的二维快照。虽然近年来出现了有希望的以学习为基础的家具组装方法,但它们假定每个组装步骤都具备正确的连接标签,而实际上价格昂贵。在本文中,我们减轻这一假设,并力求以尽可能少的人力专长和监督来解决家具组装问题。具体地说,我们假定组装的点云和目标产品的点云的可用性,并比较当前组装的点云和目标产品的点云,根据两个措施获得新的奖励信号:不正确和不完善。我们表明,我们的新奖励信号可以培养一个深网络,以便成功地组装不同类型的家具。这里可用的代码和网络是:https://github.com/METEU-KALFA/Asemble RL。