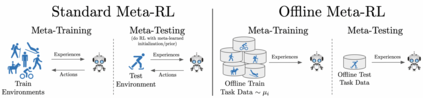
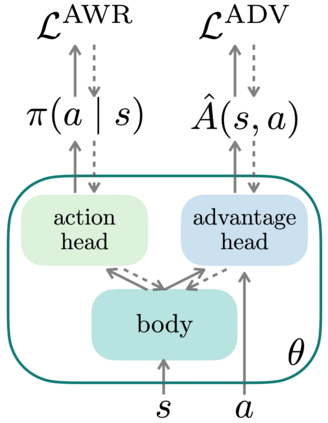
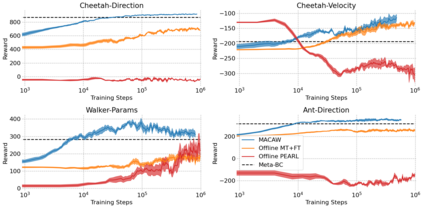
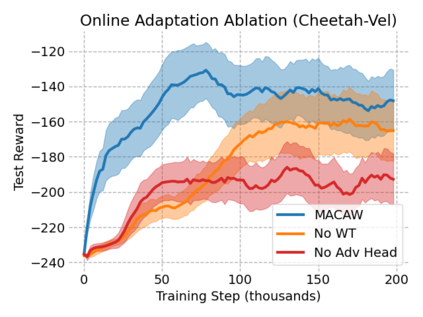
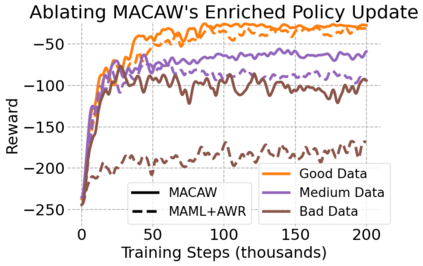
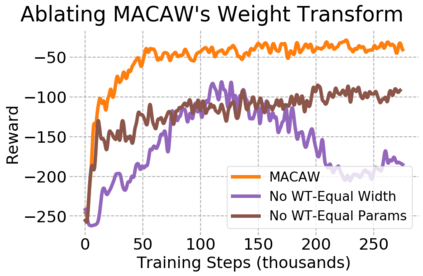
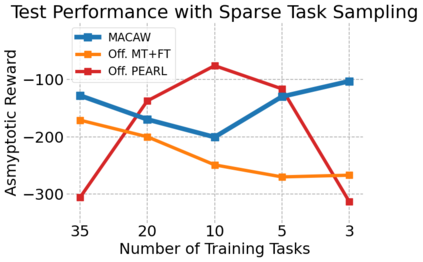
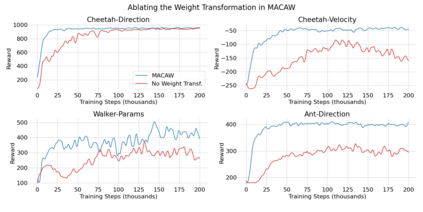
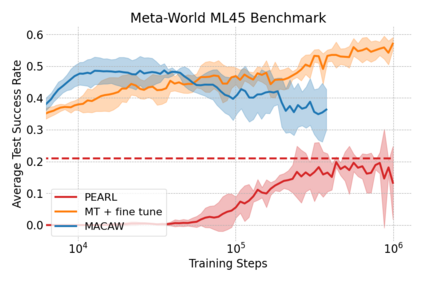
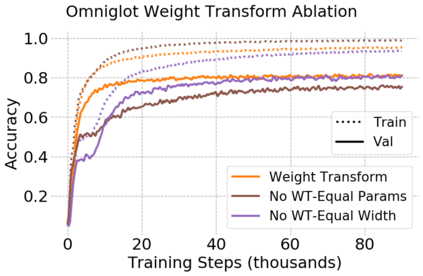
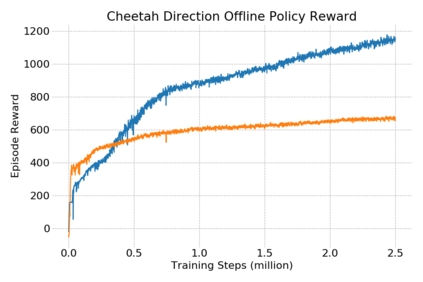
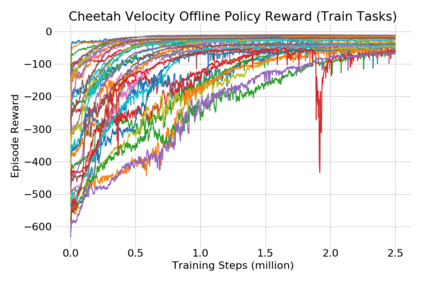
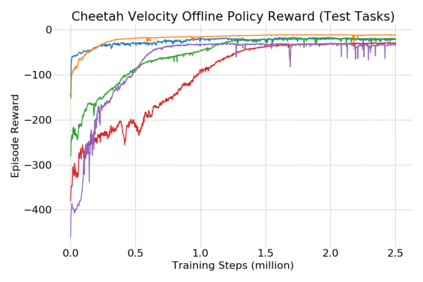
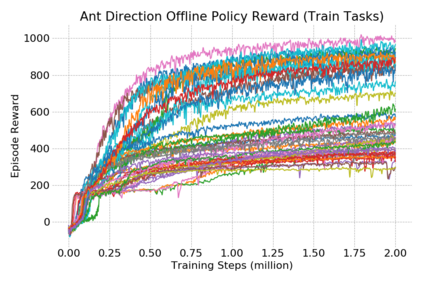
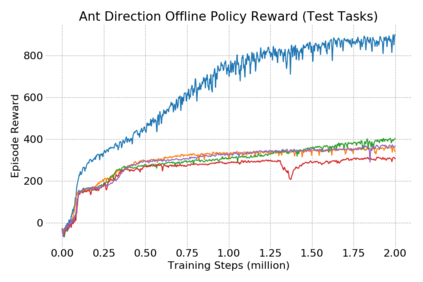
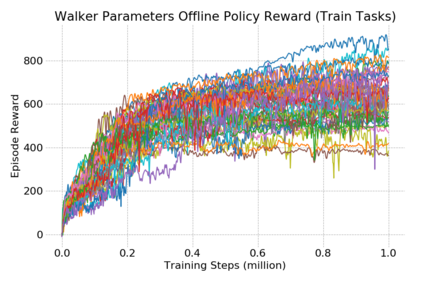
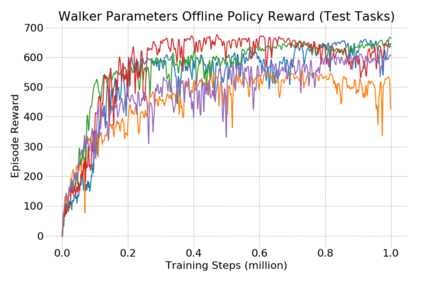
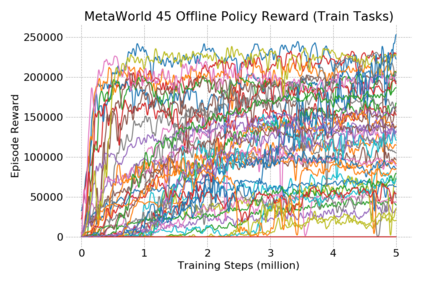
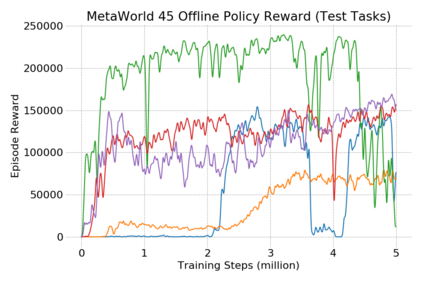
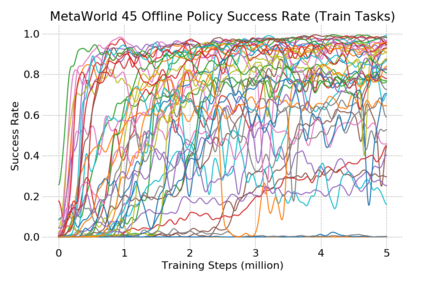
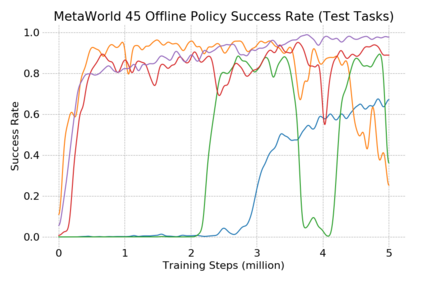
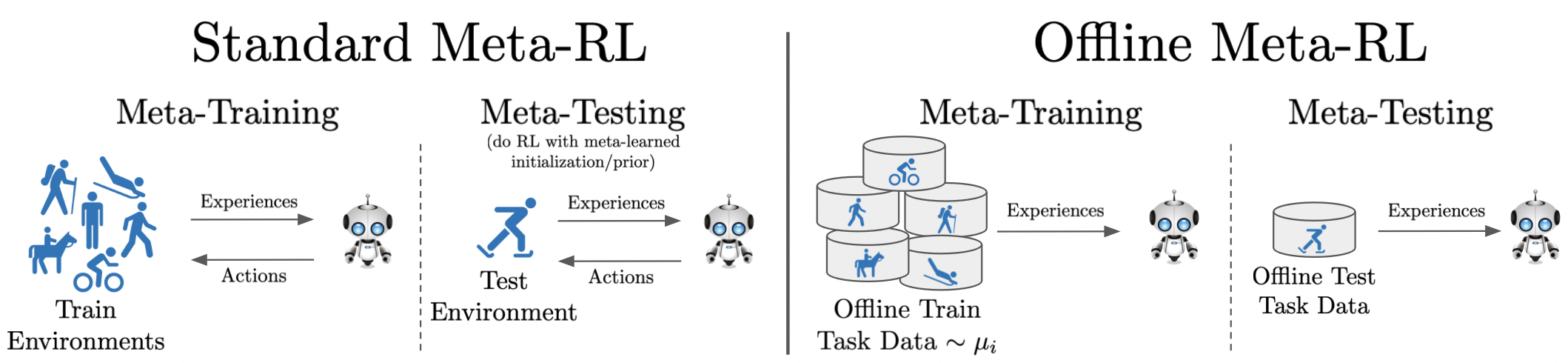
This paper introduces the offline meta-reinforcement learning (offline meta-RL) problem setting and proposes an algorithm that performs well in this setting. Offline meta-RL is analogous to the widely successful supervised learning strategy of pre-training a model on a large batch of fixed, pre-collected data (possibly from various tasks) and fine-tuning the model to a new task with relatively little data. That is, in offline meta-RL, we meta-train on fixed, pre-collected data from several tasks in order to adapt to a new task with a very small amount (less than 5 trajectories) of data from the new task. By nature of being offline, algorithms for offline meta-RL can utilize the largest possible pool of training data available and eliminate potentially unsafe or costly data collection during meta-training. This setting inherits the challenges of offline RL, but it differs significantly because offline RL does not generally consider a) transfer to new tasks or b) limited data from the test task, both of which we face in offline meta-RL. Targeting the offline meta-RL setting, we propose Meta-Actor Critic with Advantage Weighting (MACAW), an optimization-based meta-learning algorithm that uses simple, supervised regression objectives for both the inner and outer loop of meta-training. On offline variants of common meta-RL benchmarks, we empirically find that this approach enables fully offline meta-reinforcement learning and achieves notable gains over prior methods.
翻译:本文介绍了离线元加强学习(脱线元RL)问题设置,并提出了一个在这个设置中表现良好的算法。离线元加强学习(脱线元RL)类似于广泛成功、监督下的预培训模式,即对大量固定的、预收集的数据(可能来自各种任务)进行预培训,并将模型微调到新任务中,数据相对较少。也就是说,在离线元加强学习(脱线)中,我们在固定的、预收集的一些任务中,对固定的、预收集的数据进行元培训,以适应新任务,新任务中数据数量极小(低于5个目标)的新任务。从离线上看,离线的元加强学习(离线的)新任务和(b)有限的测试任务中的数据,我们既在离线进行离线的MERL数据分析,又在离线培训过程中利用最大可能不安全的或昂贵的数据收集。这就继承了离线的RL的挑战,但是,因为离线的RL一般不考虑向新的任务转移,或者从b)从测试任务中取得有限的数据,我们既在离线进行离线的离线的离线的MER结果的升级的上,我们提议在离线前的升级的升级的升级的升级的升级的模型的升级的升级的升级的升级的升级的升级的升级的升级的计算。