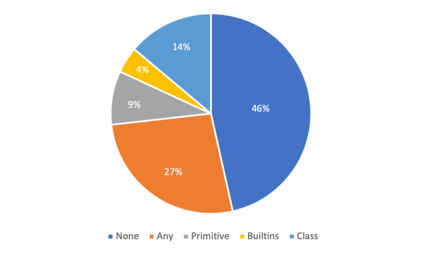
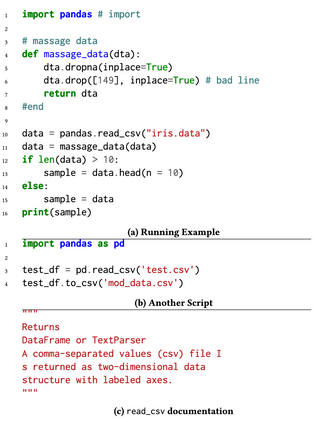
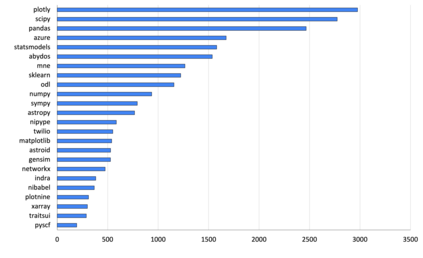
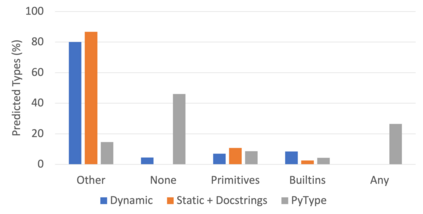
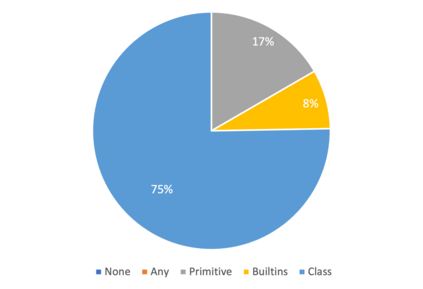
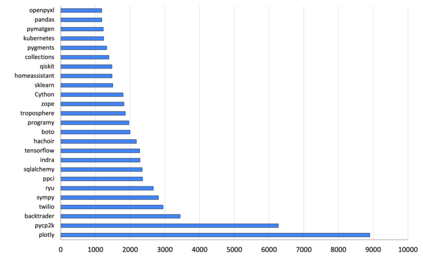
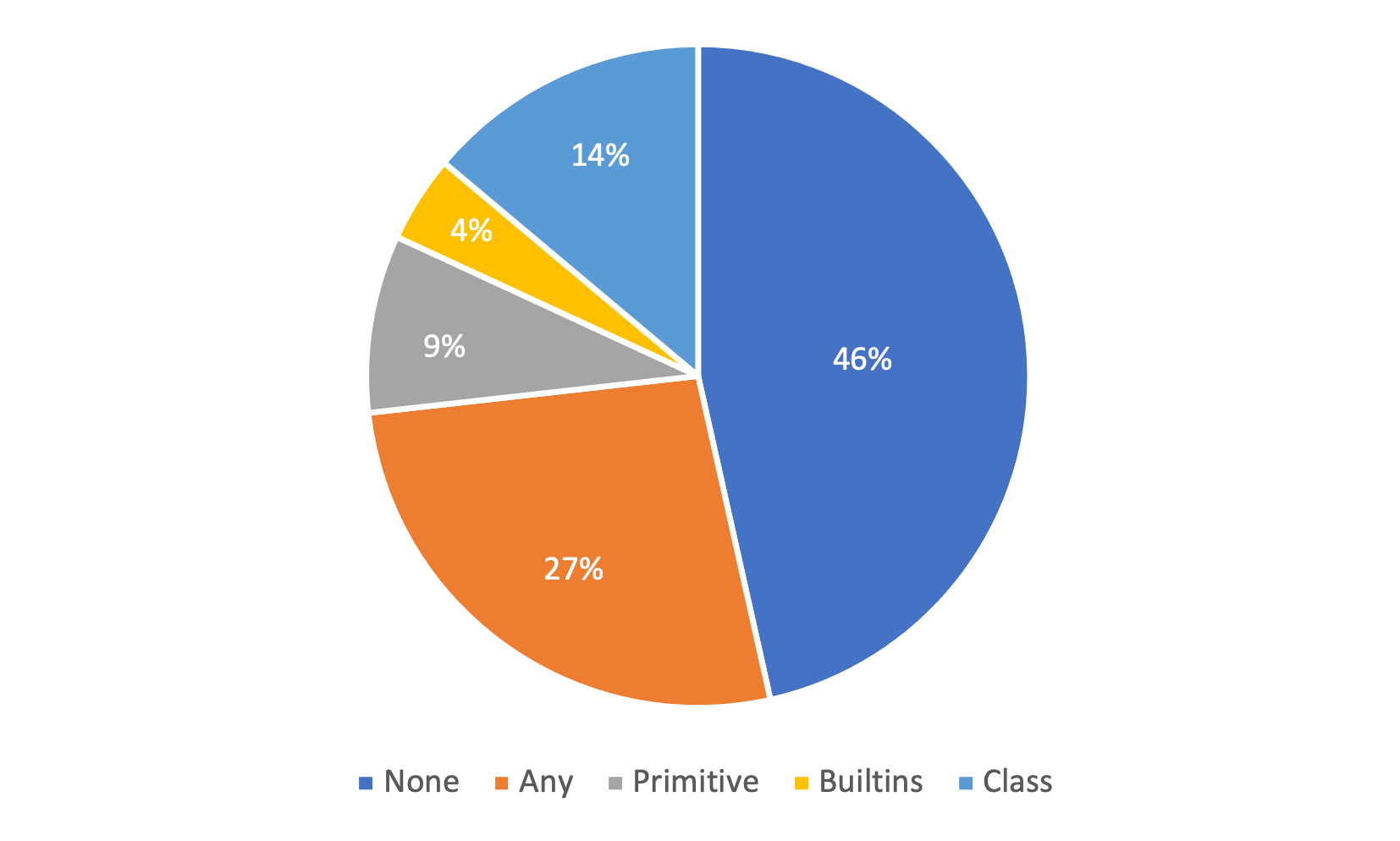
Recently, dynamically typed languages, such as Python, have gained unprecedented popularity. Although these languages alleviate the need for mandatory type annotations, types still play a critical role in program understanding and preventing runtime errors. An attractive option is to infer types automatically to get static guarantees without writing types. Existing inference techniques rely mostly on static typing tools such as PyType for direct type inference; more recently, neural type inference has been proposed. However, neural type inference is data hungry, and depends on collecting labeled data based on static typing. Such tools, however, are poor at inferring user defined types. Furthermore, type annotation by developers in these languages is quite sparse. In this work, we propose novel techniques for generating high quality types using 1) information retrieval techniques that work on well documented libraries to extract types and 2) usage patterns by analyzing a large repository of programs. Our results show that these techniques are more precise and address the weaknesses of static tools, and can be useful for generating a large labeled dataset for type inference by machine learning methods. F1 scores are 0.52-0.58 for our techniques, compared to static typing tools which are at 0.06, and we use them to generate over 37,000 types for over 700 modules.
翻译:最近,动态打字语言,如Python,获得了前所未有的流行。虽然这些语言缓解了对强制型号说明的需求,但类型在程序理解和防止运行时间错误方面仍然发挥着关键作用。一个有吸引力的选择是自动推断类型以获得静态保障,而没有写字类型。现有的推论技术主要依靠静态打字工具,如PyType,直接类型的推理;最近,提出了神经型推论。然而,神经型推论是数据饥饿,取决于基于静态打字的标签数据收集。然而,这类工具在推断用户定义类型方面仍然很薄弱。此外,用这些语言打字的写字非常少。在这项工作中,我们建议采用创新技术来生成高质量类型,使用1)信息检索技术,在有详细记录的图书馆中提取类型,2)通过分析大型程序库使用模式。我们的结果显示,这些技术更加精确,解决了静态工具的弱点,并且可以用来生成大型的标签数据集。我们用机器学习方法来推断的型号类型为型号的F1至3x5-0-0.558,我们用静式的模模模型用来制作。我们用了0.06。