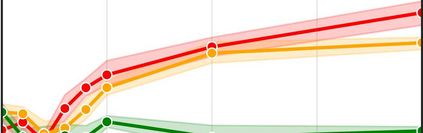
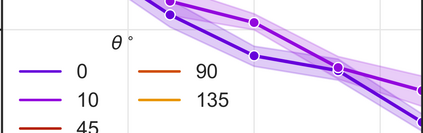
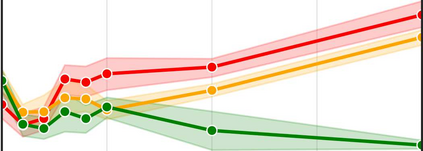
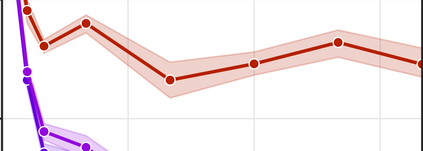
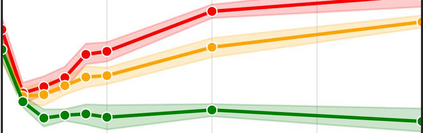
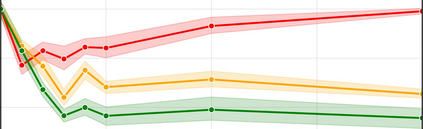
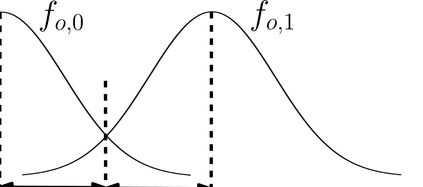
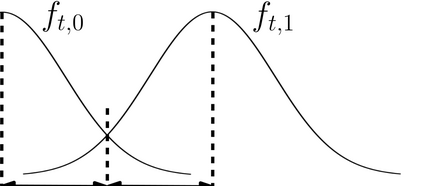
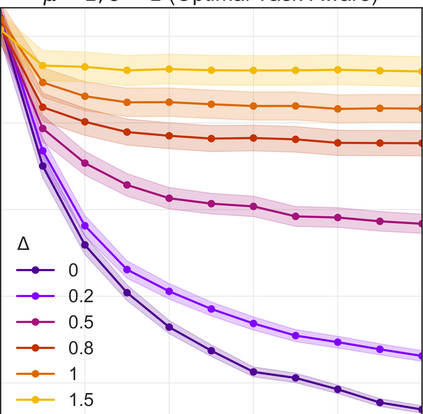
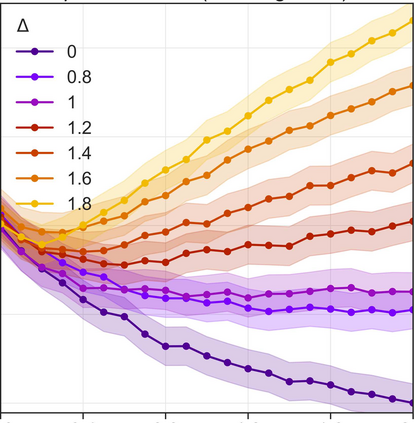
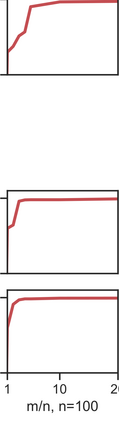
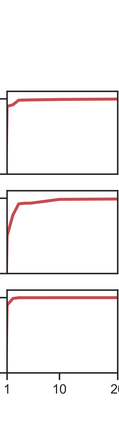
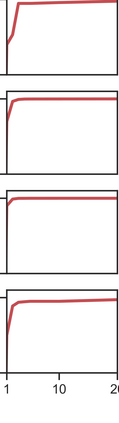
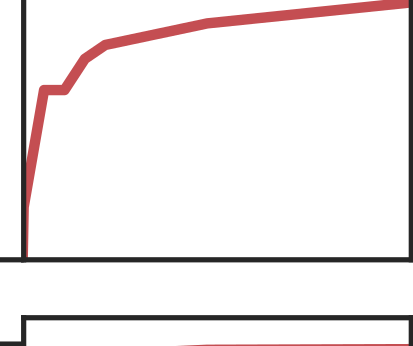
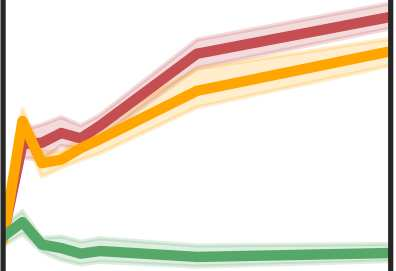
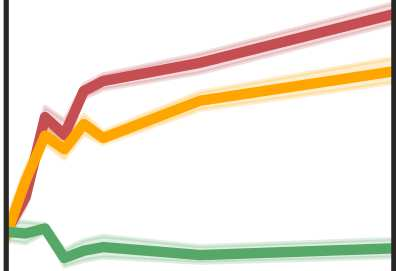
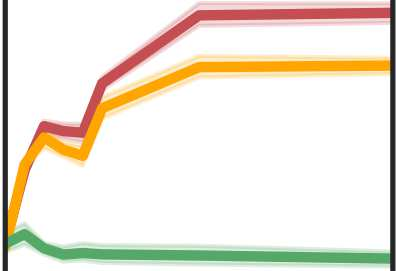
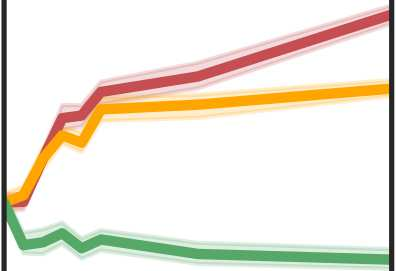
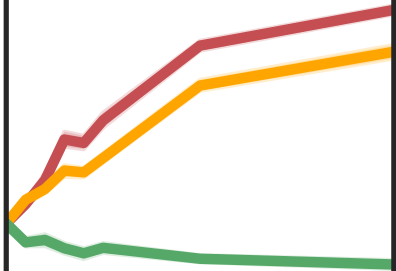
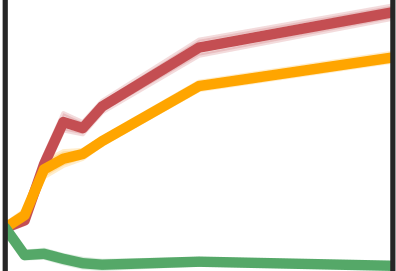
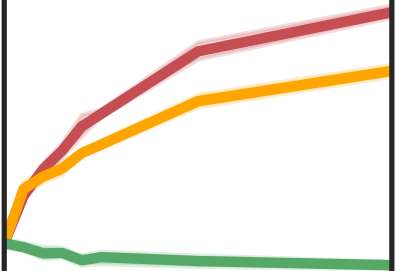
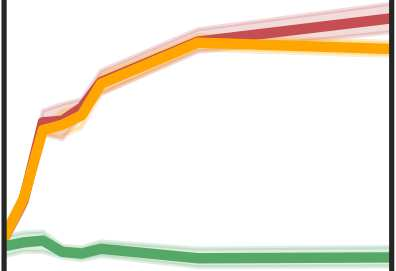
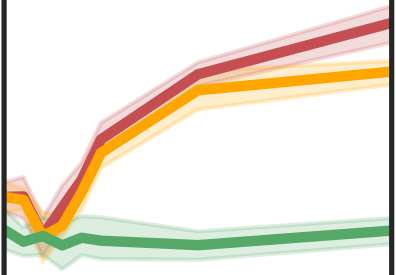
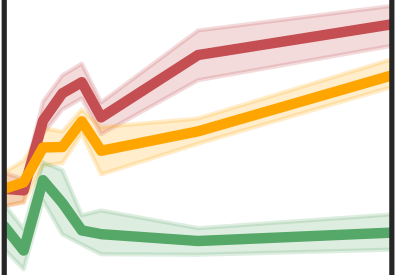
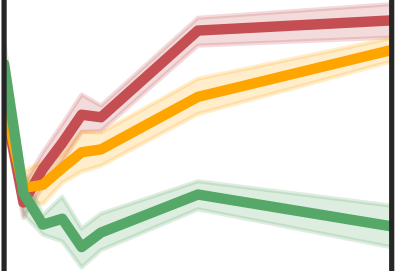
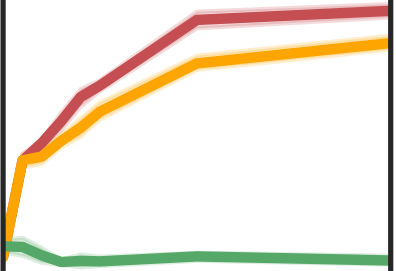
More data helps us generalize to a task. But real datasets can contain out-of-distribution (OOD) data; this can come in the form of heterogeneity such as intra-class variability but also in the form of temporal shifts or concept drifts. We demonstrate a counter-intuitive phenomenon for such problems: generalization error of the task can be a non-monotonic function of the number of OOD samples; a small number of OOD samples can improve generalization but if the number of OOD samples is beyond a threshold, then the generalization error can deteriorate. We also show that if we know which samples are OOD, then using a weighted objective between the target and OOD samples ensures that the generalization error decreases monotonically. We demonstrate and analyze this issue using linear classifiers on synthetic datasets and medium-sized neural networks on CIFAR-10.
翻译:更多的数据有助于我们将一个任务概括化。 但真实的数据集可以包含分布外(OOD)数据;这可以以不同种类的形式出现,例如类内变异,也可以以时间变化或概念漂移的形式出现。我们对这种问题展示了一种反直觉现象:任务的概括化错误可以是OOD样本数量的非分子功能;少量OOD样本可以改进概括化,但如果OOD样本的数量超过临界值,那么一般化错误就会恶化。我们还表明,如果我们知道哪些样本是OOD,然后使用目标样本和OOOD样本之间的加权目标,就能确保普遍性错误的单一减少。我们用合成数据集和CIFAR-10上的中等神经网络的线性分类仪来演示和分析这一问题。