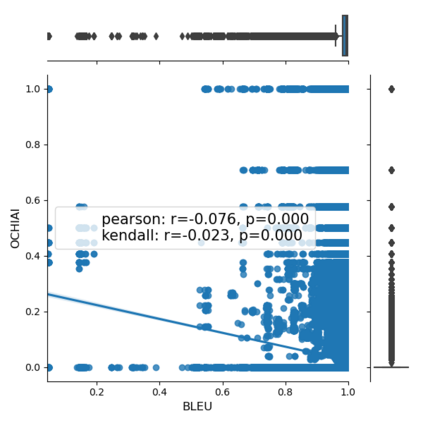
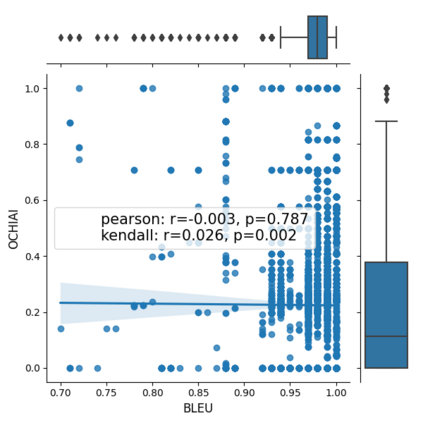
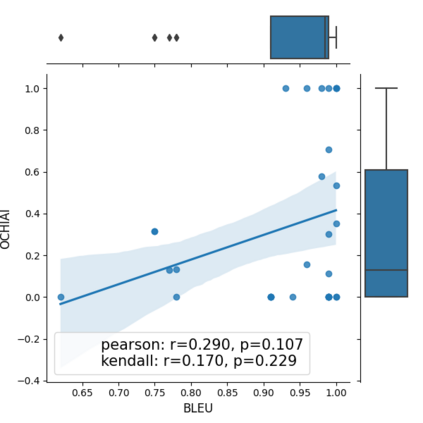
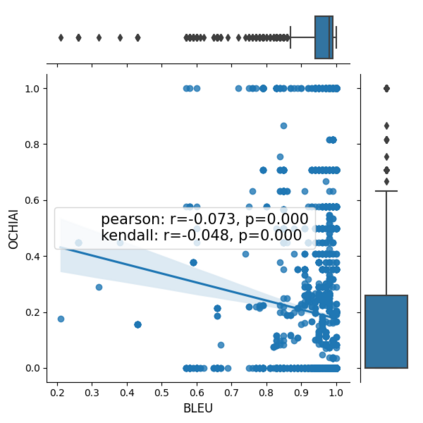
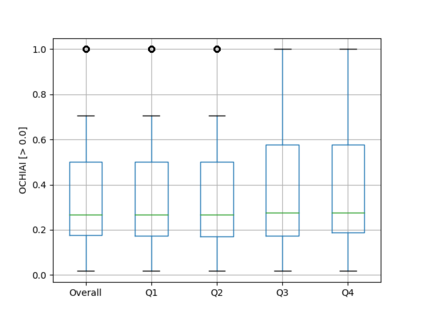
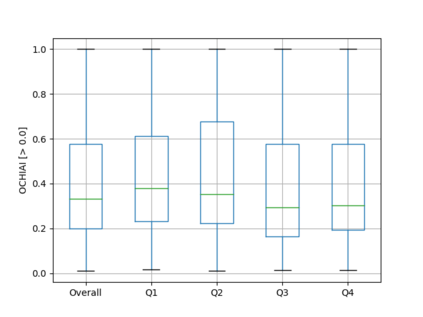
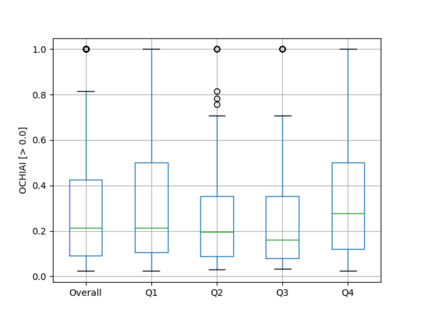
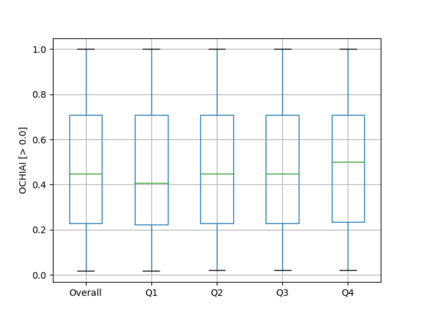
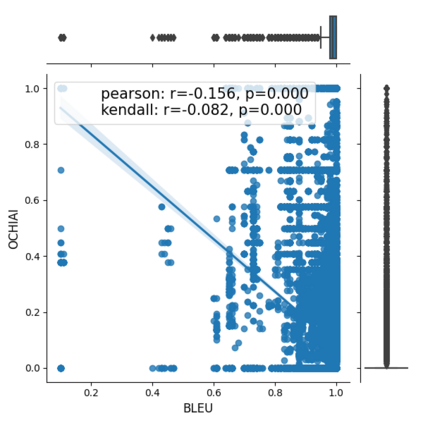
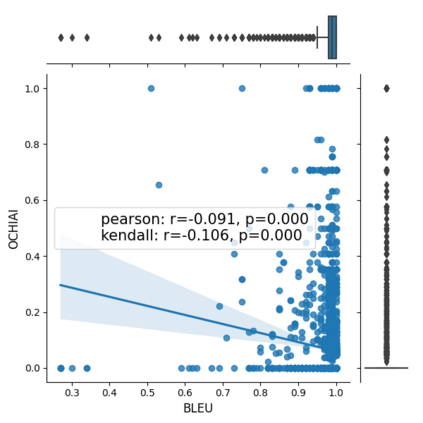
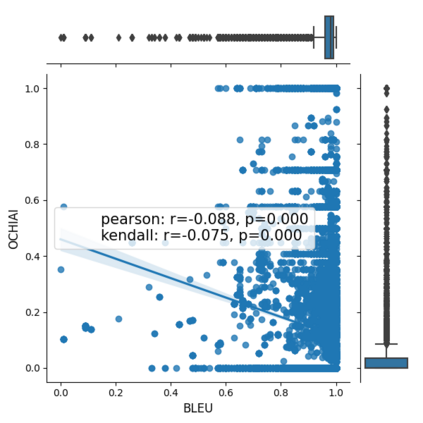
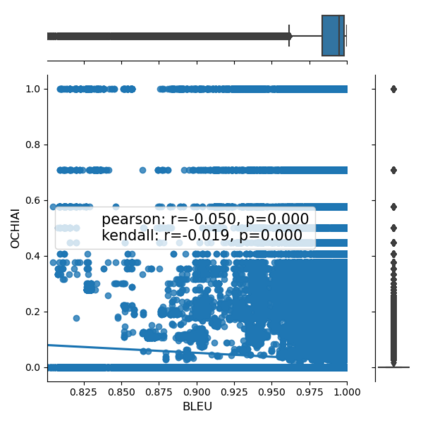
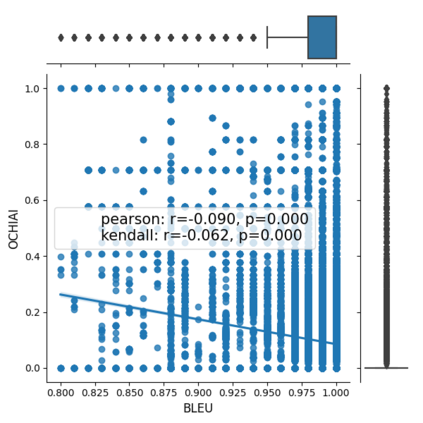
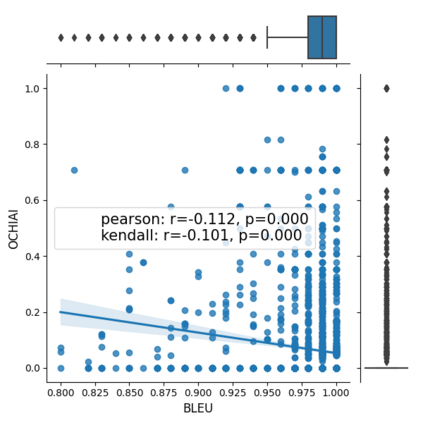
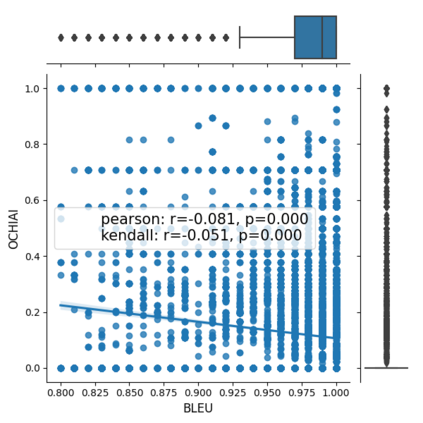
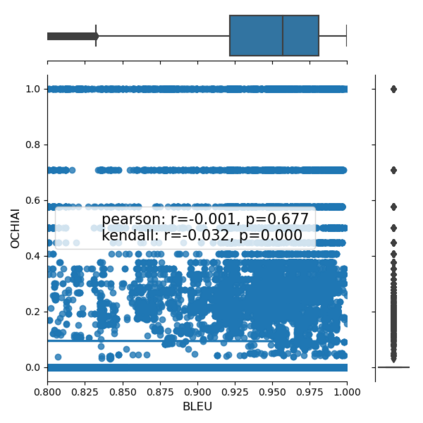
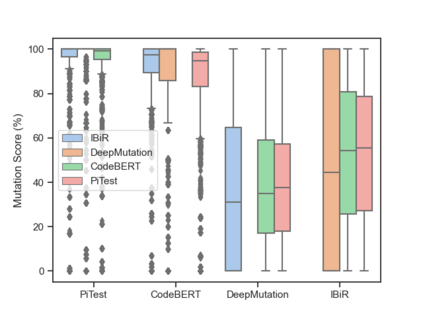
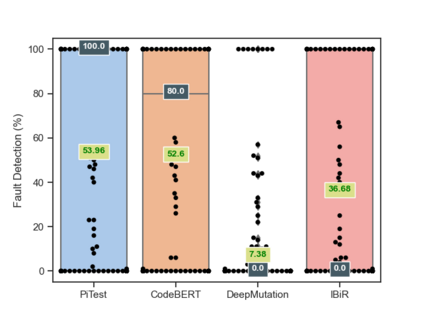
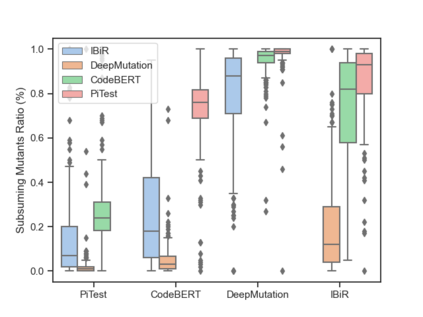
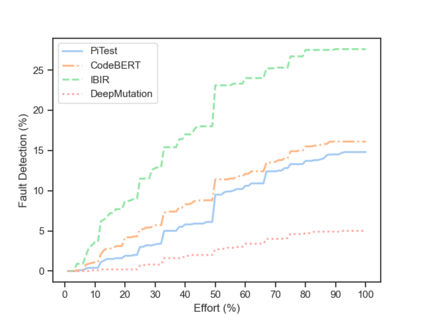
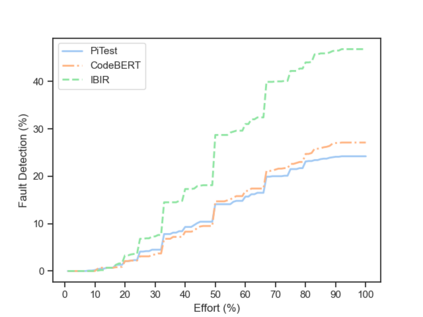
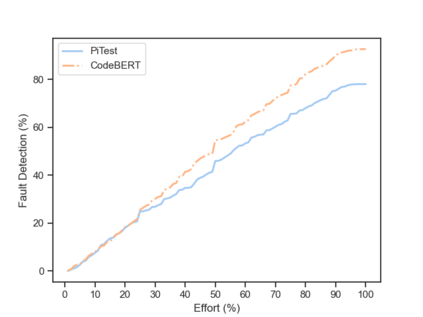
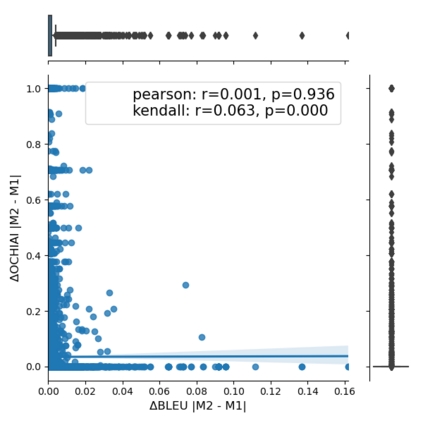
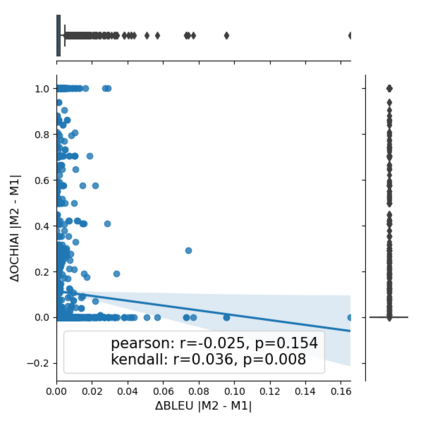
Fault seeding is typically used in controlled studies to evaluate and compare test techniques. Central to these techniques lies the hypothesis that artificially seeded faults involve some form of realistic properties and thus provide realistic experimental results. In an attempt to strengthen realism, a recent line of research uses advanced machine learning techniques, such as deep learning and Natural Language Processing (NLP), to seed faults that look like (syntactically) real ones, implying that fault realism is related to syntactic similarity. This raises the question of whether seeding syntactically similar faults indeed results in semantically similar faults and more generally whether syntactically dissimilar faults are far away (semantically) from the real ones. We answer this question by employing 4 fault-seeding techniques (PiTest - a popular mutation testing tool, IBIR - a tool with manually crafted fault patterns, DeepMutation - a learning-based fault seeded framework and CodeBERT - a novel mutation testing tool that use code embeddings) and demonstrate that syntactic similarity does not reflect semantic similarity. We also show that 60%, 47%, 43%, and 7% of the real faults of Defects4J V2 are semantically resembled by CodeBERT, PiTest, IBIR, and DeepMutation faults. We then perform an objective comparison between the techniques and find that CodeBERT and PiTest have similar fault detection capabilities that subsume IBIR and DeepMutation, and that IBIR is the most cost-effective technique. Moreover, the overall fault detection of PiTest, CodeBERT, IBIR, and DeepMutation was, on average, 54%, 53%, 37%, and 7%.
翻译:这些技术的核心在于人工种子断层是否包含某种形式现实的特性,从而提供现实的实验结果。为了加强现实主义,最近的一系列研究使用了先进的机器学习技术,例如深层学习和自然语言处理(NLP),以产生看上去像(在实际操作上)真实的(在实际操作上)的缺陷,意味着现实错误与同系方法相似。这提出了下述问题:在视觉学学上相似的断层是否确实导致语义相似的断层,更一般地说,断层的断层是否与真实的(模拟)相距遥远。为了加强现实主义,最近的一系列研究使用了先进的机器学习技术,例如深层学习和自然语言处理(NLPP),用来制造看上去像(在实际操作上)真实的断层的断层(在实际操作上)测试工具,深层导道-基于学习的断层框架和代码BERT-一种使用代码嵌入的新型突变异测试工具,在深度的IB2、深度和深度的断层(我们显示)和深度的断层的断层的断层性(在实际的解析中)和精确的解析中的解)。