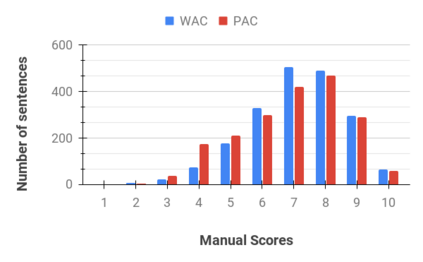
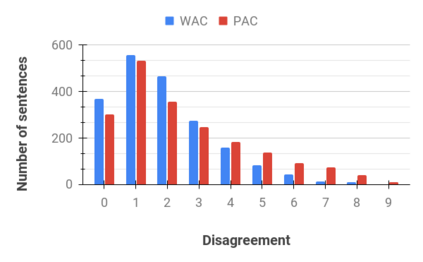
Text generation is a highly active area of research in the computational linguistic community. The evaluation of the generated text is a challenging task and multiple theories and metrics have been proposed over the years. Unfortunately, text generation and evaluation are relatively understudied due to the scarcity of high-quality resources in code-mixed languages where the words and phrases from multiple languages are mixed in a single utterance of text and speech. To address this challenge, we present a corpus (HinGE) for a widely popular code-mixed language Hinglish (code-mixing of Hindi and English languages). HinGE has Hinglish sentences generated by humans as well as two rule-based algorithms corresponding to the parallel Hindi-English sentences. In addition, we demonstrate the inefficacy of widely-used evaluation metrics on the code-mixed data. The HinGE dataset will facilitate the progress of natural language generation research in code-mixed languages.
翻译:生成文本是计算语言社区中一个非常活跃的研究领域。对生成文本的评估是一项艰巨的任务,多年来提出了多种理论和衡量标准。不幸的是,由于代码混合语言的文字和短语在文本和语言的单一表述中混杂在一起,因此,由于代码混合语言的高质量资源稀缺,文本生成和评价相对缺乏研究。为了应对这一挑战,我们为广泛流行的编码混合语言Hinglish(印地语和英语的编码混合)提供了一套资料(HinGE)。HinGE拥有由人类生成的Hingish语句和与印地语-英语平行句相对对应的两种基于规则的算法。此外,我们展示了在代码混合数据上广泛使用的评价指标是无效的。HinGE数据集将促进以代码混合语言进行天然语言生成研究的进展。