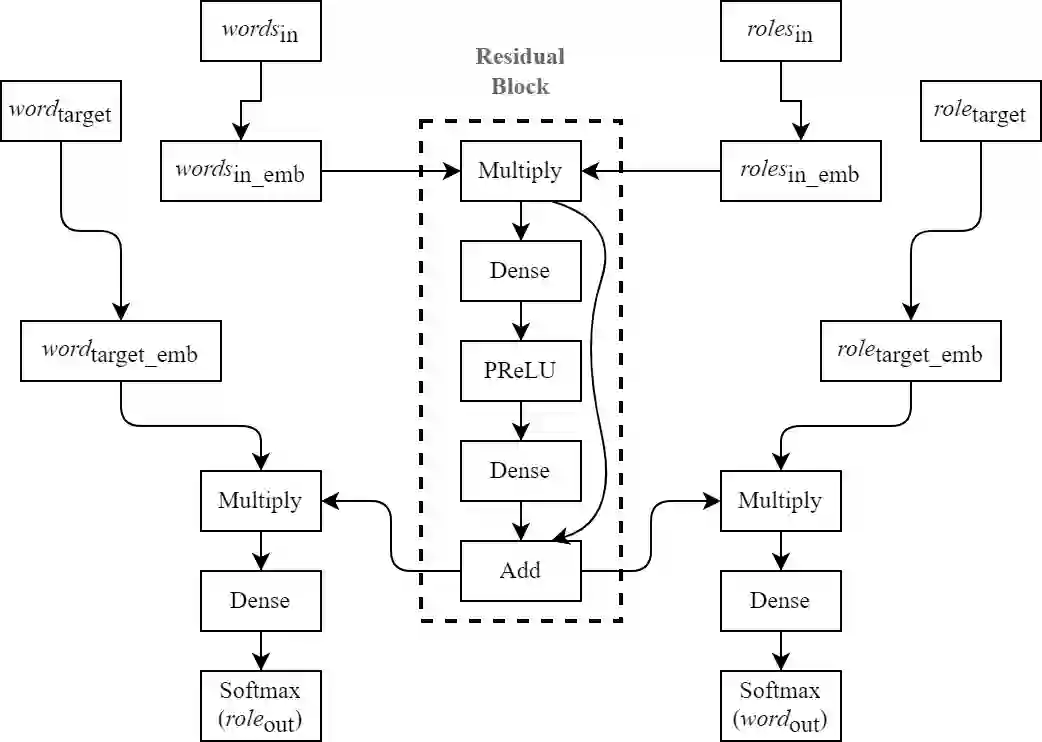
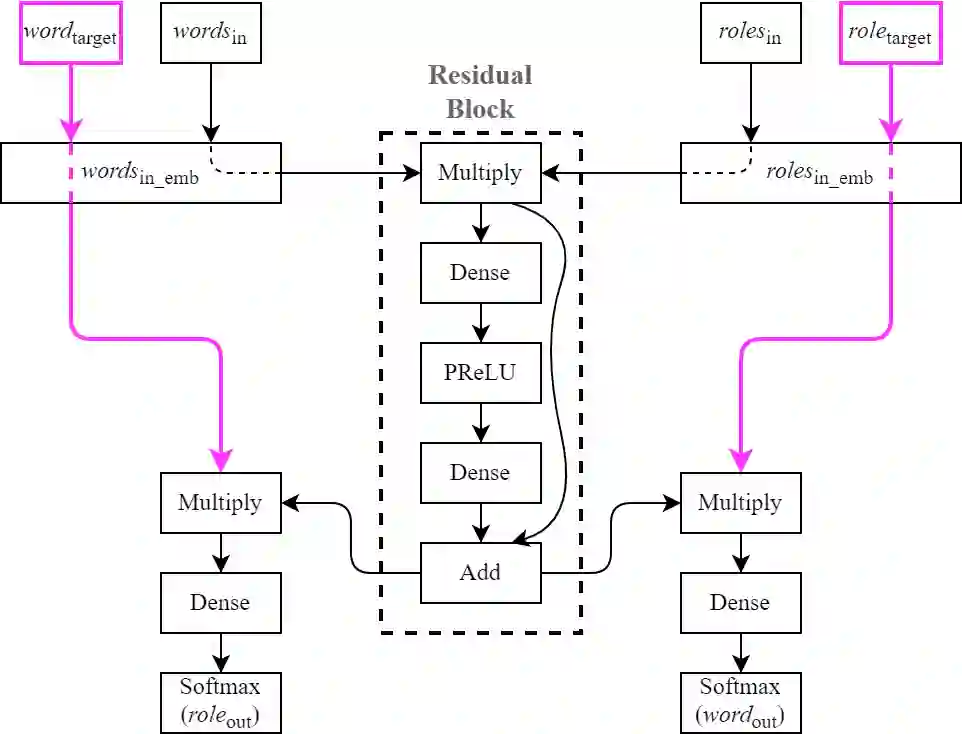
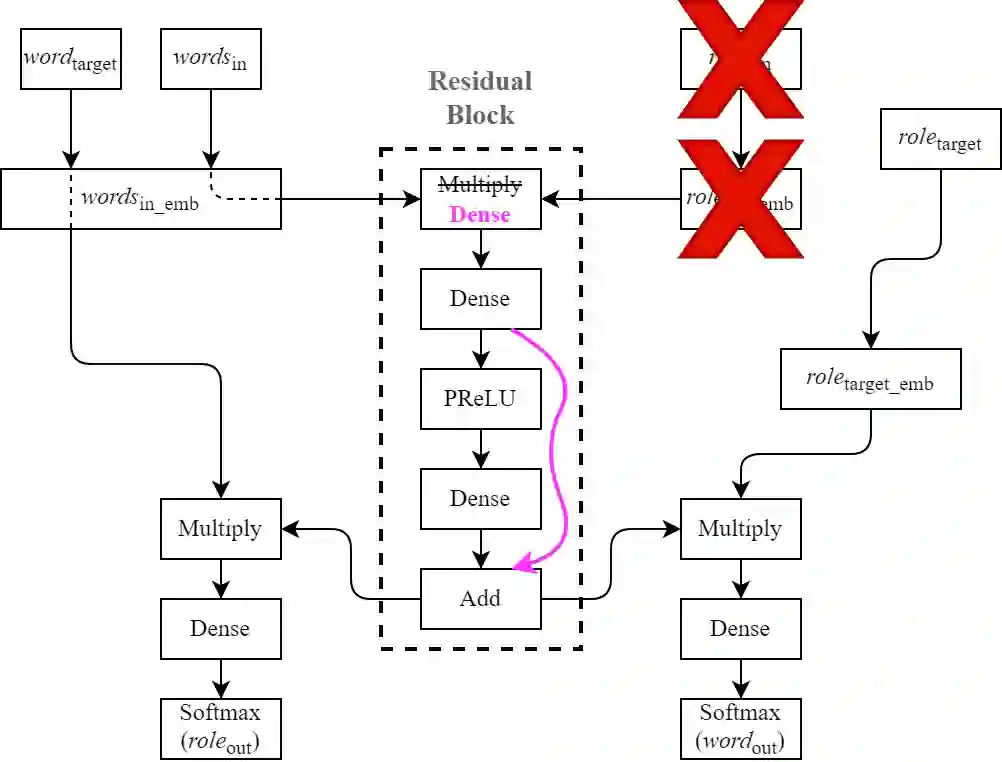
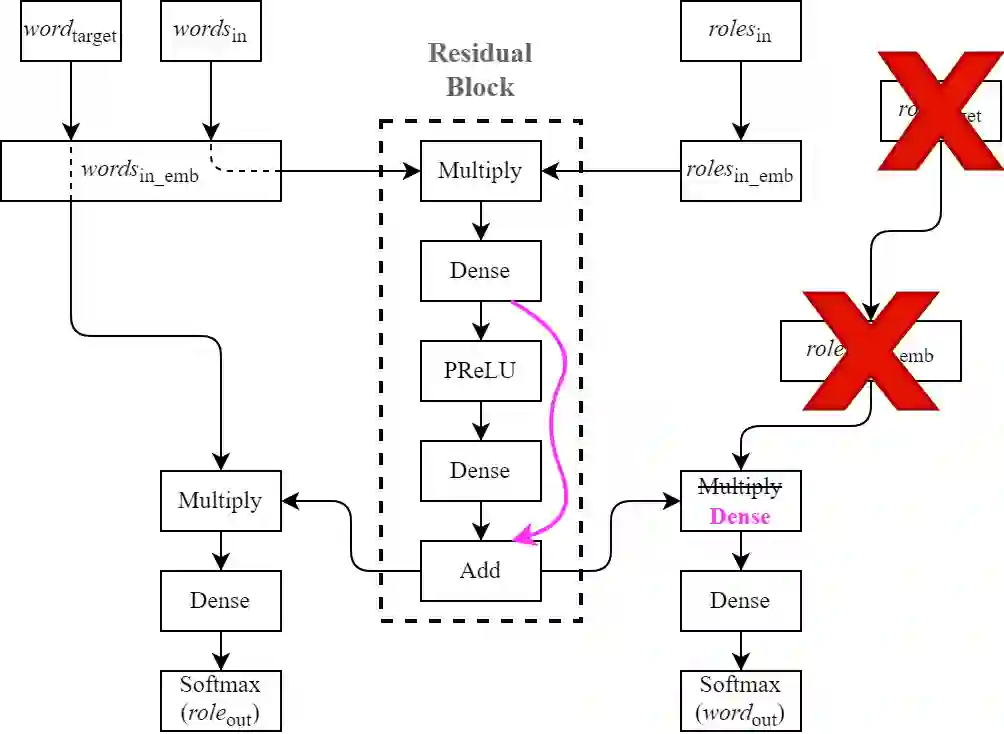
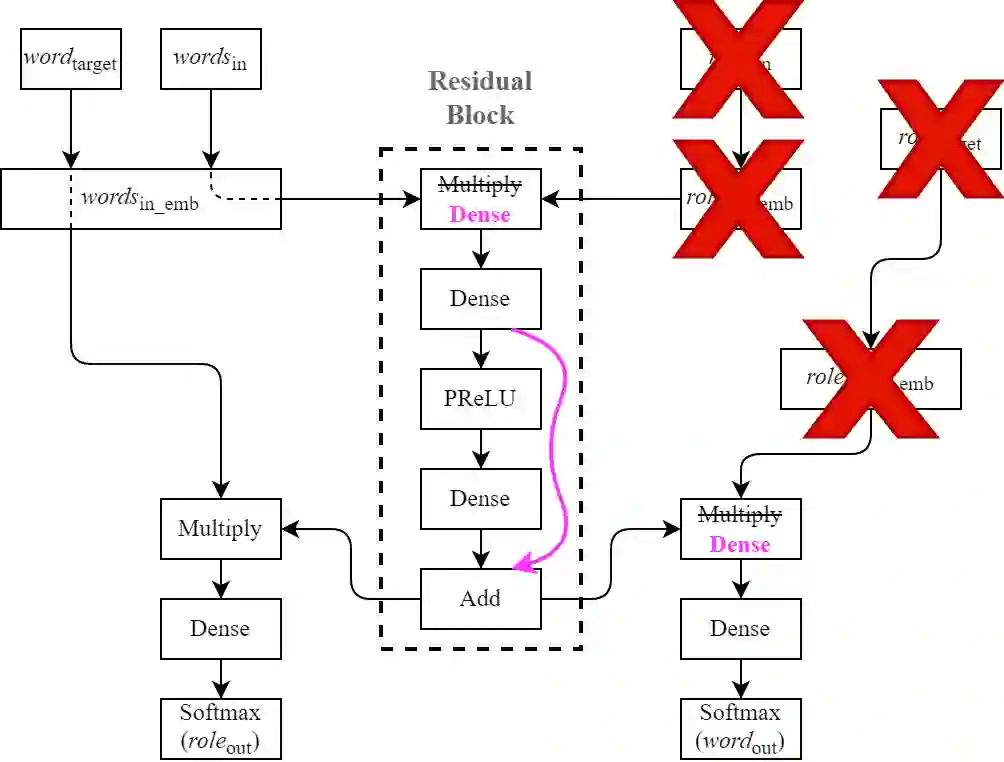
Observing that for certain NLP tasks, such as semantic role prediction or thematic fit estimation, random embeddings perform as well as pretrained embeddings, we explore what settings allow for this and examine where most of the learning is encoded: the word embeddings, the semantic role embeddings, or ``the network''. We find nuanced answers, depending on the task and its relation to the training objective. We examine these representation learning aspects in multi-task learning, where role prediction and role-filling are supervised tasks, while several thematic fit tasks are outside the models' direct supervision. We observe a non-monotonous relation between some tasks' quality score and the training data size. In order to better understand this observation, we analyze these results using easier, per-verb versions of these tasks.
翻译:我们观察到,对于诸如语义角色预测或主题适合性估计等某些国家语言方案的任务,随机嵌入既能起到作用,又能起到预先训练的嵌入作用,我们探索了哪些环境允许这样做,并检查了大部分学习内容的编码:单词嵌入、语义角色嵌入或“网络”。我们根据任务及其与培训目标的关系找到细微的答案。我们在多任务学习中考察了这些代表性学习方面,在多任务学习中,角色预测和角色填充是受监督的任务,而一些主题适合性的任务则不在模型的直接监督范围之内。我们观察了一些任务的质量分数和培训数据大小之间的非同质关系。为了更好地了解这一观察,我们用这些任务的简单、按每种语言的版本来分析这些结果。