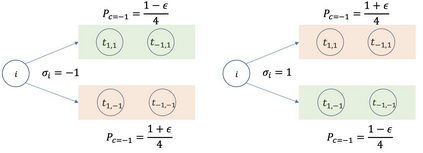
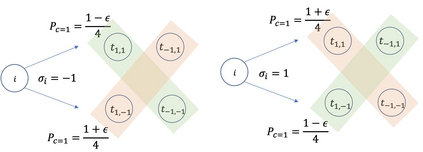
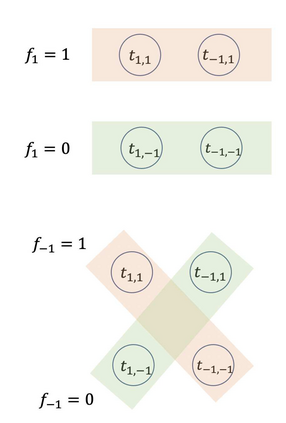
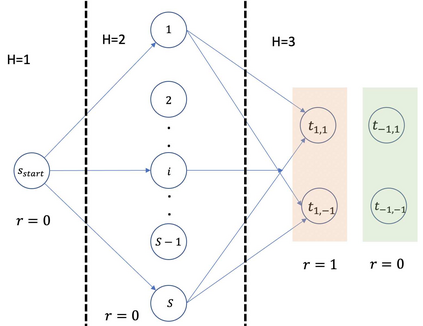
This paper considers batch Reinforcement Learning (RL) with general value function approximation. Our study investigates the minimal assumptions to reliably estimate/minimize Bellman error, and characterizes the generalization performance by (local) Rademacher complexities of general function classes, which makes initial steps in bridging the gap between statistical learning theory and batch RL. Concretely, we view the Bellman error as a surrogate loss for the optimality gap, and prove the followings: (1) In double sampling regime, the excess risk of Empirical Risk Minimizer (ERM) is bounded by the Rademacher complexity of the function class. (2) In the single sampling regime, sample-efficient risk minimization is not possible without further assumptions, regardless of algorithms. However, with completeness assumptions, the excess risk of FQI and a minimax style algorithm can be again bounded by the Rademacher complexity of the corresponding function classes. (3) Fast statistical rates can be achieved by using tools of local Rademacher complexity. Our analysis covers a wide range of function classes, including finite classes, linear spaces, kernel spaces, sparse linear features, etc.
翻译:本文审视了具有一般价值功能近似值的批量强化学习(RL) 。 我们的研究调查了用于可靠估计/最小化Bellman错误的最低限度假设,并描述一般功能类别(当地)Rademacher复杂程度的概括性表现,这为缩小统计学习理论与批RL之间的差距迈出了初步步骤。 具体地说,我们认为Bellman错误是最佳性差距的替代损失,并证明以下各点:(1) 在双重抽样制度下,经验风险最小化(ERM)的过重风险受功能类别Rademacher复杂性的束缚。 (2) 在单一取样制度中,无论算法如何,取样效率风险最小化不可能在没有进一步假设的情况下实现,但是,如果假设完整,FQI和微轴式算法的超重风险可以再次与相应的功能类别Rademacher复杂性联系在一起。(3) 使用地方Rademacher复杂程度的工具可以实现快速统计率。我们的分析涵盖广泛的功能类别,包括有限的类别、线性空间、内核空间、细线性线性特征等。