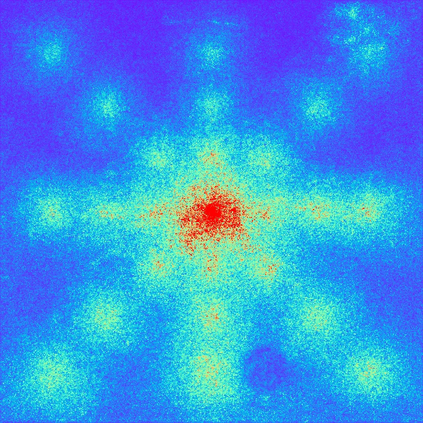
We present SegFormer, a simple, efficient yet powerful semantic segmentation framework which unifies Transformers with lightweight multilayer perception (MLP) decoders. SegFormer has two appealing features: 1) SegFormer comprises a novel hierarchically structured Transformer encoder which outputs multiscale features. It does not need positional encoding, thereby avoiding the interpolation of positional codes which leads to decreased performance when the testing resolution differs from training. 2) SegFormer avoids complex decoders. The proposed MLP decoder aggregates information from different layers, and thus combining both local attention and global attention to render powerful representations. We show that this simple and lightweight design is the key to efficient segmentation on Transformers. We scale our approach up to obtain a series of models from SegFormer-B0 to SegFormer-B5, reaching significantly better performance and efficiency than previous counterparts. For example, SegFormer-B4 achieves 50.3% mIoU on ADE20K with 64M parameters, being 5x smaller and 2.2% better than the previous best method. Our best model, SegFormer-B5, achieves 84.0% mIoU on Cityscapes validation set and shows excellent zero-shot robustness on Cityscapes-C. Code will be released at: github.com/NVlabs/SegFormer.
翻译:我们介绍SegFormer, 是一个简单、高效但强大的语义分解框架, 使具有轻量级多层认知的变异器( MLP) 解码器统一起来。 SegFormer 有两个吸引人的特性:(1) SegFormer 由一个新的分级结构化变异器编码器组成, 产生多尺度的特性。 它不需要定位编码, 从而避免定位码的内插, 从而在测试分辨率不同于培训时导致性能下降。 (2) SegFormer 避免复杂的解码器。 拟议的 MLP 解码器将不同层次的信息集中起来, 从而将当地注意力和全球注意力结合起来, 以进行强有力的表达。 我们显示, 这个简单和轻重的设计是变异器高效分解的关键。 我们扩大我们的方法, 以获得一系列模型, 从SegFormer-B0到SegFormer-B5, 其性能和效率大大高于以前的对应器。 例如, SegFormer- I 将比以前的最佳方法小5ximmer-C- browestalalalalations 将实现B5。