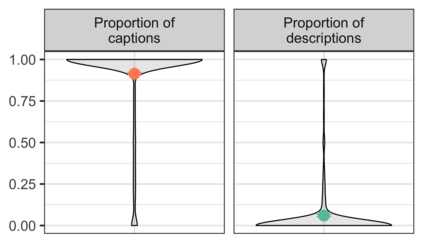
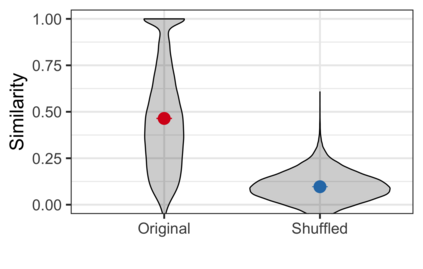
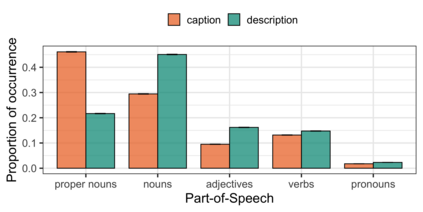
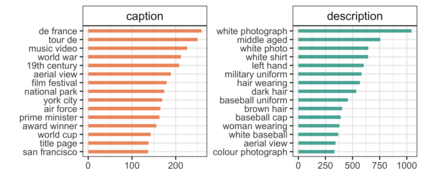
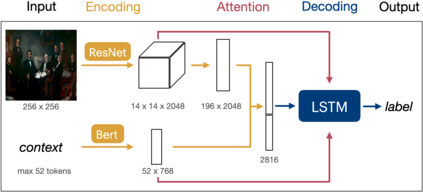
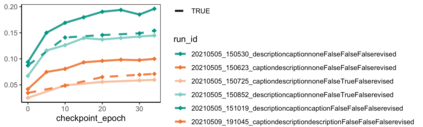
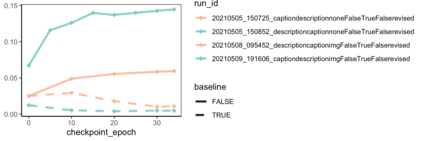
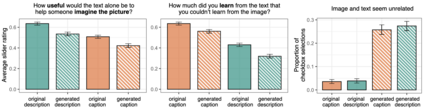
Images have become an integral part of online media. This has enhanced the dissemination of knowledge, but it poses serious accessibility challenges. The HTML "alt" field is hidden by default and designated for supplying a description that could replace the image, but it is rarely used. By contrast, image captions appear alongside the image and are more abundant, but they are written to supply additional information and generally lack the details required for accessibility. These terms are often treated as synonyms, but we argue that a distinction is essential. To address this, we introduce the publicly available Wikipedia-based corpus Concadia, which consists of 96,918 images with corresponding English-language descriptions, captions, and surrounding context. We use Concadia to characterize the commonalities and differences between descriptions and captions. This leads us to the hypothesis that captions, while not substitutes for descriptions, can provide a useful signal for creating effective descriptions. We substantiate this hypothesis by showing that image description systems trained on Concadia benefit from having caption embeddings as part of their inputs. Finally, we provide evidence from a human-subjects experiment that human-created captions and descriptions have distinct communicative purposes, and that our generated texts follow this same pattern. These experiments begin to show how Concadia can be a powerful tool in addressing the underlying accessibility issues posed by image data.
翻译:图像已经成为在线媒体不可分割的一部分。 这加强了知识传播, 但带来了严重的无障碍挑战 。 HTML “ alt” 字段默认隐藏, 指定用于提供可以替换图像的描述, 但很少使用。 相反, 图像标题出现在图像旁边, 并且更加丰富, 但是它们是写来提供补充信息, 并且一般缺乏访问所需的细节 。 这些术语通常被视为同义词, 但我们认为区别很重要 。 为了解决这个问题, 我们引入了基于 维基百科的 Concadia 软件, 其中包括96 918 个图像, 并配有相应的英语描述、 说明和周围环境。 我们使用 Concadia 来描述描述描述描述描述和说明之间的共性和差异。 这导致我们的假设是, 标题虽然不是描述的替代品, 却可以为创建有效描述提供有用的信号。 我们用Concadia 培训过的图像描述系统, 通过将字幕嵌入作为投入的一部分, 来证实这一假设。 最后, 我们从人类实验中提供证据, 人类创建的描述和描述具有鲜明的版本, 来显示Con 的图像的版本是如何生成的。