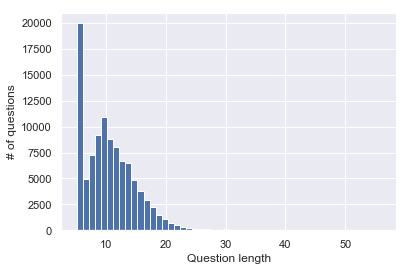
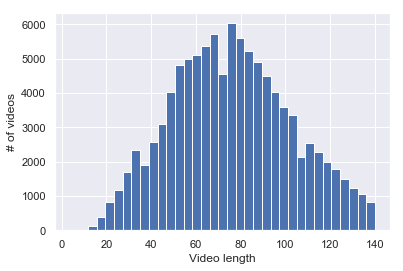
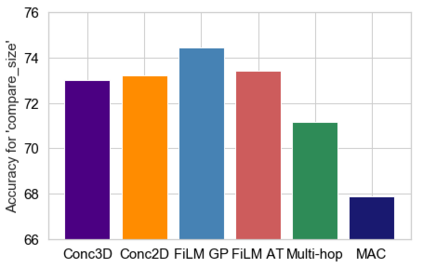
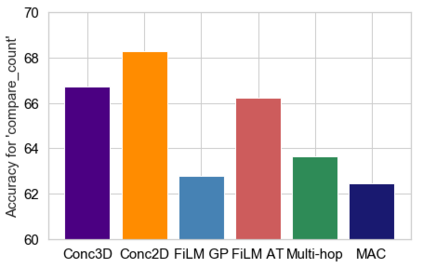
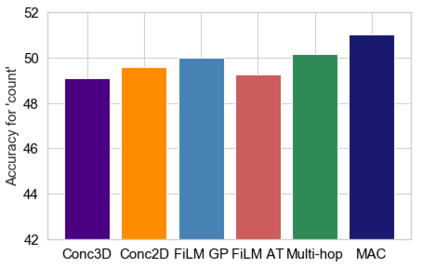
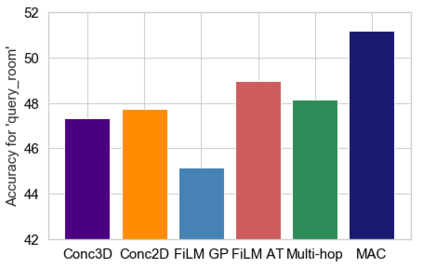
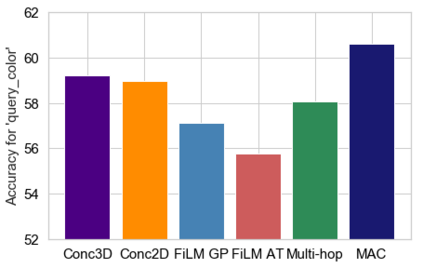
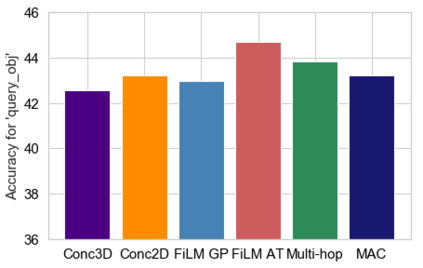
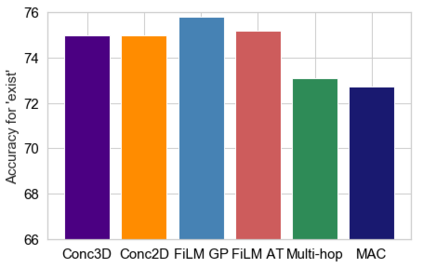
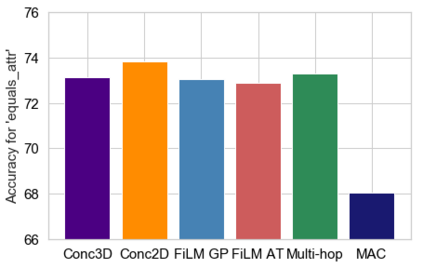
Embodied Question Answering (EQA) is a recently proposed task, where an agent is placed in a rich 3D environment and must act based solely on its egocentric input to answer a given question. The desired outcome is that the agent learns to combine capabilities such as scene understanding, navigation and language understanding in order to perform complex reasoning in the visual world. However, initial advancements combining standard vision and language methods with imitation and reinforcement learning algorithms have shown EQA might be too complex and challenging for these techniques. In order to investigate the feasibility of EQA-type tasks, we build the VideoNavQA dataset that contains pairs of questions and videos generated in the House3D environment. The goal of this dataset is to assess question-answering performance from nearly-ideal navigation paths, while considering a much more complete variety of questions than current instantiations of the EQA task. We investigate several models, adapted from popular VQA methods, on this new benchmark. This establishes an initial understanding of how well VQA-style methods can perform within this novel EQA paradigm.
翻译:在线问答(EQA)是最近提出的一项任务,在这种任务中,一个代理机构被安置在丰富的三维环境中,必须仅仅基于其以自我为中心的输入来回答一个特定问题。期望的结果是,代理机构学会将现场理解、导航和语言理解等能力结合起来,以便在视觉世界中进行复杂的推理。然而,将标准愿景和语言方法与模仿和强化学习算法相结合的初步进展显示,EQA对这些技术来说可能过于复杂和具有挑战性。为了调查EQA类型任务的可行性,我们建立了视频NavQA数据集,其中包含在House3D环境中产生的问题和视频组合。这一数据集的目的是评估近理想导航路径的问答性能,同时考虑远比目前对 EQA 任务的即时态更完整的各种问题。我们根据流行的VQA 方法,根据这一新的基准对几个模式进行了调整。这初步了解了VQA类方法在这种新型的 EQA 范式模型中能够如何运行。