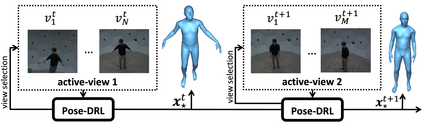
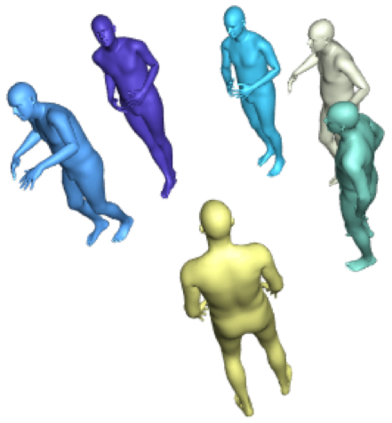
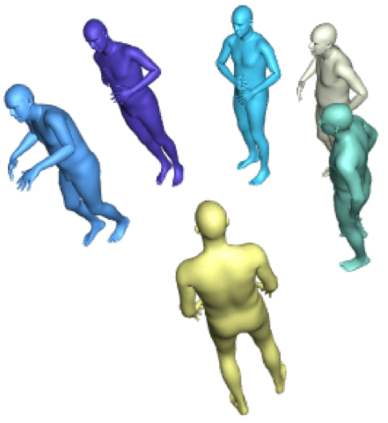
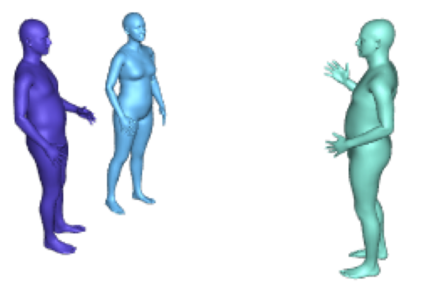
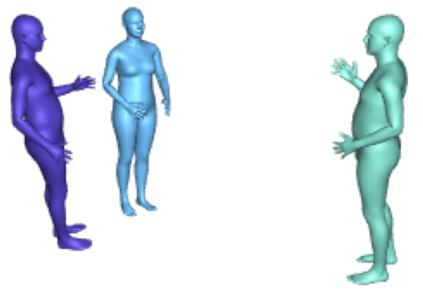
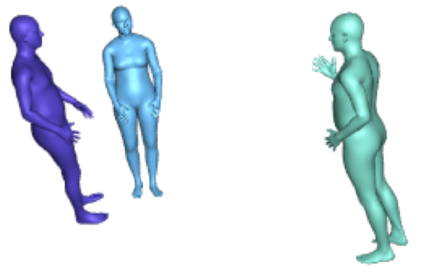
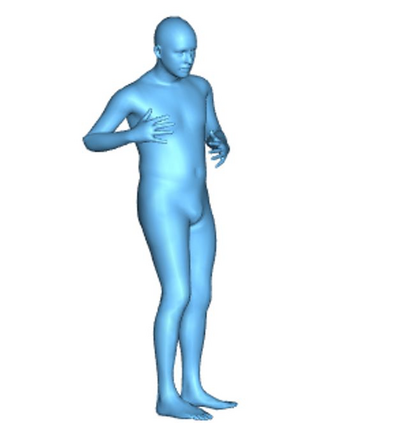
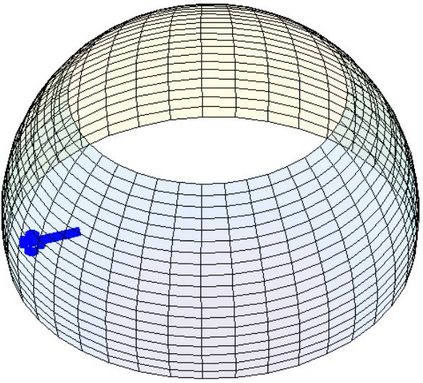
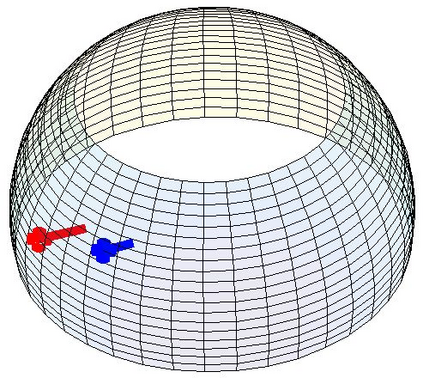
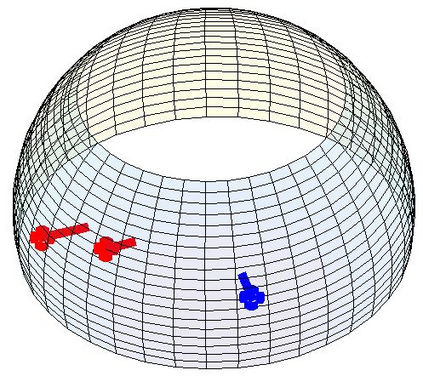
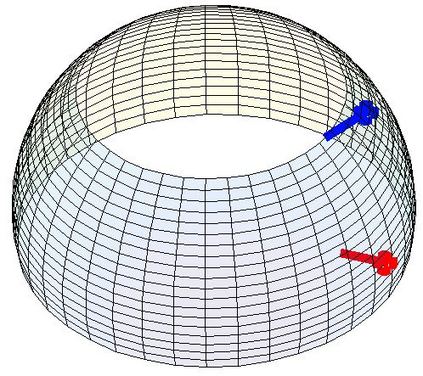
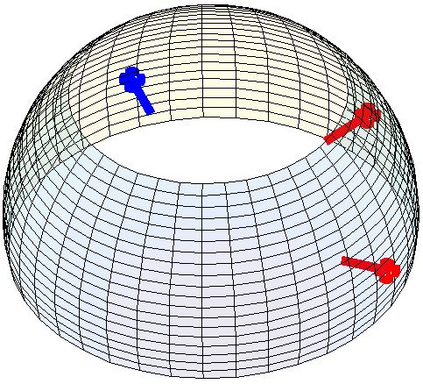
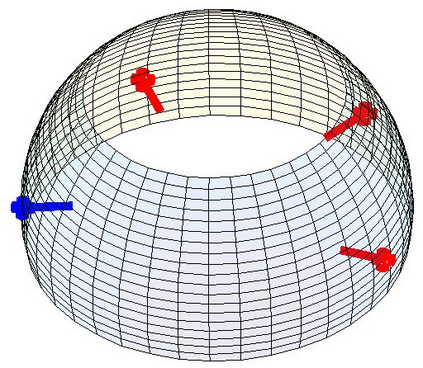
Most 3d human pose estimation methods assume that input -- be it images of a scene collected from one or several viewpoints, or from a video -- is given. Consequently, they focus on estimates leveraging prior knowledge and measurement by fusing information spatially and/or temporally, whenever available. In this paper we address the problem of an active observer with freedom to move and explore the scene spatially -- in `time-freeze' mode -- and/or temporally, by selecting informative viewpoints that improve its estimation accuracy. Towards this end, we introduce Pose-DRL, a fully trainable deep reinforcement learning-based active pose estimation architecture which learns to select appropriate views, in space and time, to feed an underlying monocular pose estimator. We evaluate our model using single- and multi-target estimators with strong result in both settings. Our system further learns automatic stopping conditions in time and transition functions to the next temporal processing step in videos. In extensive experiments with the Panoptic multi-view setup, and for complex scenes containing multiple people, we show that our model learns to select viewpoints that yield significantly more accurate pose estimates compared to strong multi-view baselines.
翻译:多数3人构成估计方法都假定输入 -- -- 无论是从一个或几个角度或从一个视频中收集的场景的图像,还是从一个视频中收集的场景的图像 -- -- 已经给出。因此,它们侧重于通过在空间和/或时间上尽可能利用现有信息来利用先前的知识和测量的估计数。在本文件中,我们处理空间上自由移动和探索场景的积极观察者的问题 -- -- 采用“时间冻结”模式 -- -- 和/或时间上,选择信息性观点,以提高其估计准确性。为此,我们引入了一种完全可训练的深强化学习的基于学习的积极场景估计结构Pose-DRL,这种结构在空间和时间上学会选择适当的观点,用来喂养一个潜在的单方形图像估计仪。我们用单方和多目标估计仪来评估我们的模型,在两种环境中都有很强的结果。我们的系统进一步学习在时间和过渡功能上自动停止条件,在视频的下一个时间处理步骤。在与全景多视图设置的广泛实验中,对于包含多个人的复杂场景,我们展示模型学会选择能够产生显著更精确的图像估计的观点。