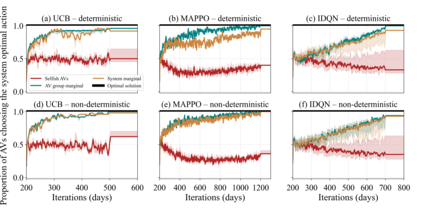
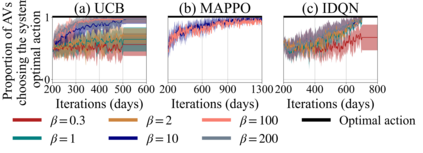
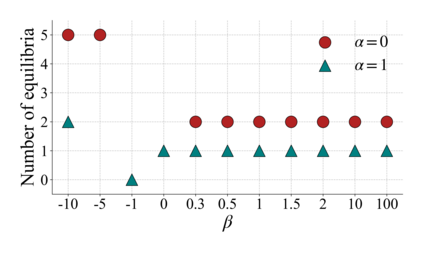
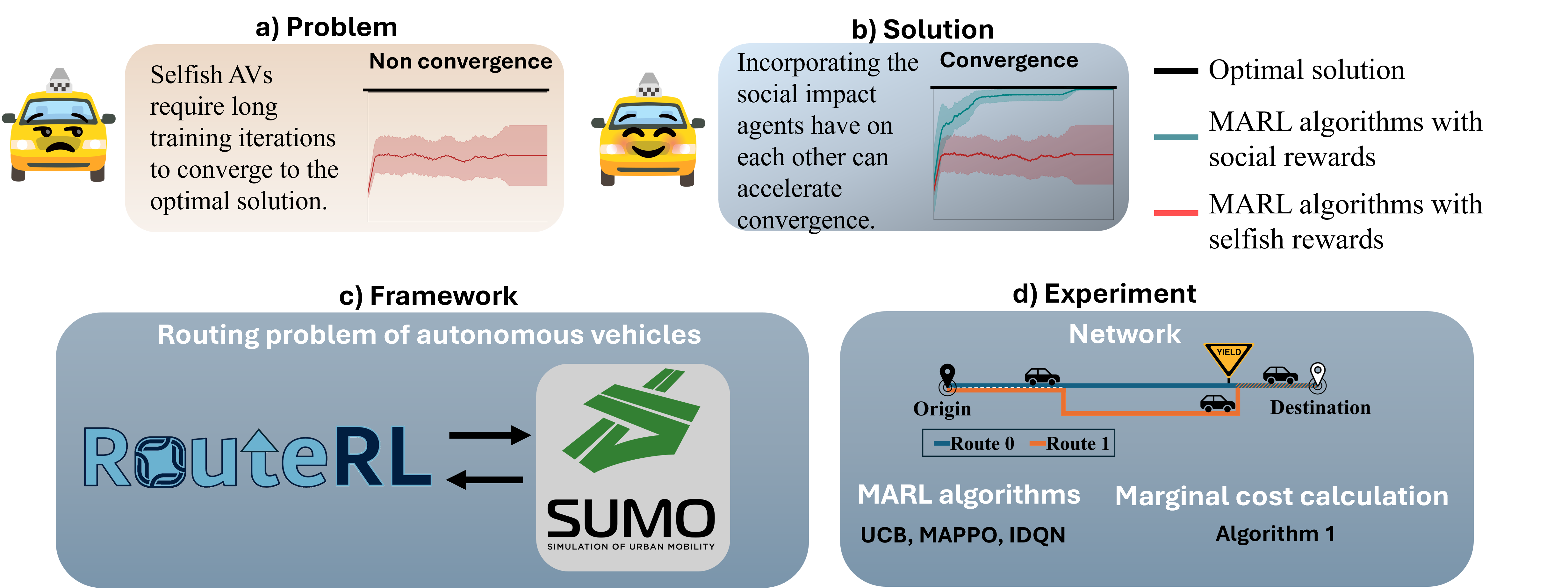
Previous work has shown that when multiple selfish Autonomous Vehicles (AVs) are introduced to future cities and start learning optimal routing strategies using Multi-Agent Reinforcement Learning (MARL), they may destabilize traffic systems, as they would require a significant amount of time to converge to the optimal solution, equivalent to years of real-world commuting. We demonstrate that moving beyond the selfish component in the reward significantly relieves this issue. If each AV, apart from minimizing its own travel time, aims to reduce its impact on the system, this will be beneficial not only for the system-wide performance but also for each individual player in this routing game. By introducing an intrinsic reward signal based on the marginal cost matrix, we significantly reduce training time and achieve convergence more reliably. Marginal cost quantifies the impact of each individual action (route-choice) on the system (total travel time). Including it as one of the components of the reward can reduce the degree of non-stationarity by aligning agents' objectives. Notably, the proposed counterfactual formulation preserves the system's equilibria and avoids oscillations. Our experiments show that training MARL algorithms with our novel reward formulation enables the agents to converge to the optimal solution, whereas the baseline algorithms fail to do so. We show these effects in both a toy network and the real-world network of Saint-Arnoult. Our results optimistically indicate that social awareness (i.e., including marginal costs in routing decisions) improves both the system-wide and individual performance of future urban systems with AVs.
翻译:暂无翻译