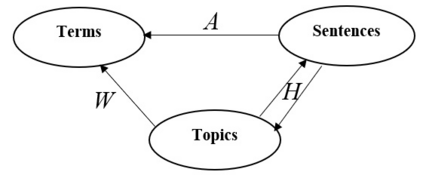
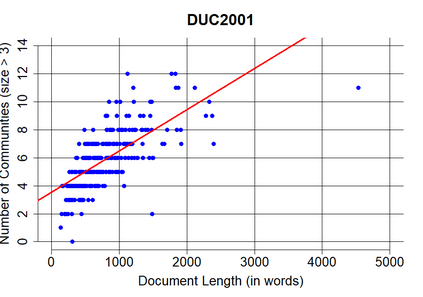
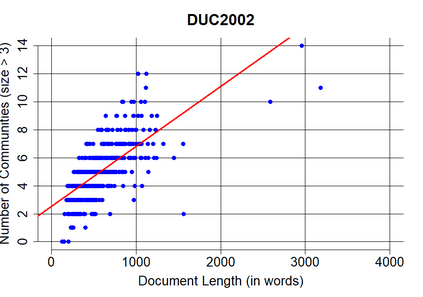
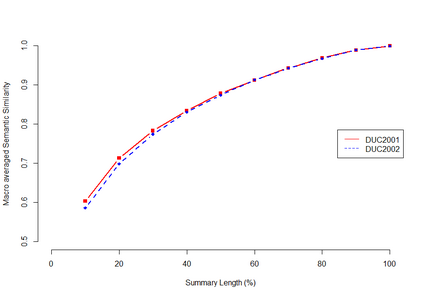
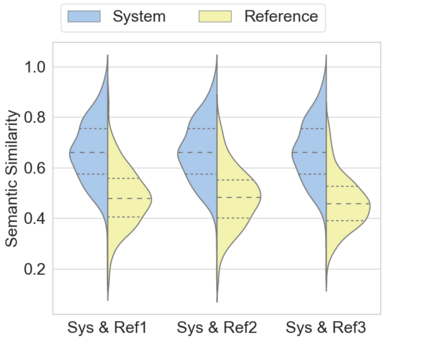
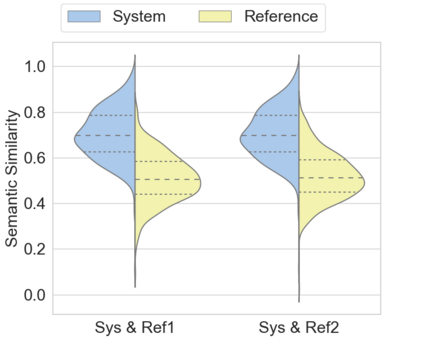
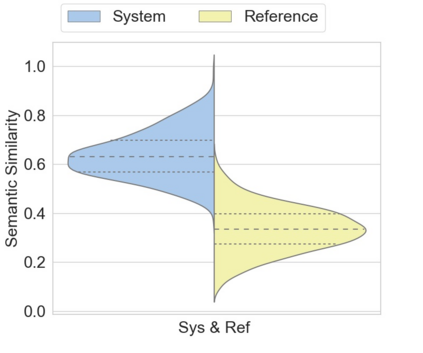
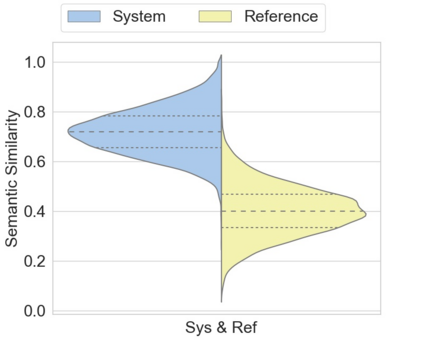
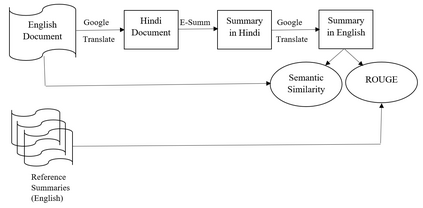
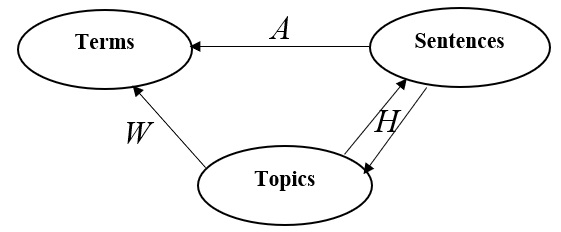
Automatic text summarization aims to cut down readers time and cognitive effort by reducing the content of a text document without compromising on its essence. Ergo, informativeness is the prime attribute of document summary generated by an algorithm, and selecting sentences that capture the essence of a document is the primary goal of extractive document summarization. In this paper, we employ Shannon entropy to capture informativeness of sentences. We employ Non-negative Matrix Factorization (NMF) to reveal probability distributions for computing entropy of terms, topics, and sentences in latent space. We present an information theoretic interpretation of the computed entropy, which is the bedrock of the proposed E-Summ algorithm, an unsupervised method for extractive document summarization. The algorithm systematically applies information theoretic principle for selecting informative sentences from important topics in the document. The proposed algorithm is generic and fast, and hence amenable to use for summarization of documents in real time. Furthermore, it is domain-, collection-independent and agnostic to the language of the document. Benefiting from strictly positive NMF factor matrices, E-Summ algorithm is transparent and explainable too. We use standard ROUGE toolkit for performance evaluation of the proposed method on four well known public data-sets. We also perform quantitative assessment of E-Summ summary quality by computing its semantic similarity w.r.t the original document. Our investigation reveals that though using NMF and information theoretic approach for document summarization promises efficient, explainable, and language independent text summarization, it needs to be bolstered to match the performance of deep neural methods.
翻译:自动文本总和的目的是通过减少文本文件的内容来减少阅读时间和认知努力,而不会损害其精髓。 Ergo, 信息性是由算法产生的文件摘要的主要属性, 选择能捕捉文件精髓的句子是抽取性文件总和的首要目标。 在本文中, 我们使用香农 辛普利 来捕捉判决的丰富性。 我们使用非负性矩阵系数( NMF) 来显示隐蔽空间中计算术语、 主题和句子的编码的概率分布。 我们展示了对计算成的英特罗比的理论解释, 这是拟议的E- Summ 算法的基础, 是用于提取文件精选文件精选的不超超超超超导性的文件摘要。 计算法系统系统地应用信息性能原则从文件中选取信息性句子, 并且可以实时使用非负性的文件总和可变数方法对文件语言进行计算。 我们从严格正性 NMFI 要素矩阵中获取的精度矩阵, E- Sudealalalalalal ass exalalal ex ex ex ex ex ex ex laction us lacurrup laviolview lacument us laview laview laview lacument laut the supal laut laut laut lautus lautus lautus lautus laut laut lautus laut lautal lautus laut laut lax laut lax labild lax lax lax lax ex lax laut laut laut laut laut laut exal ex ex ex ex ex ex ex ex ex ex ex ex ex ex ex exal exal exal exal ex ex ex ex exal labal lautal laut laut ex ex ex lautus wewe we we we we we we we we we we we we we we we we we we we we we we we we we we we