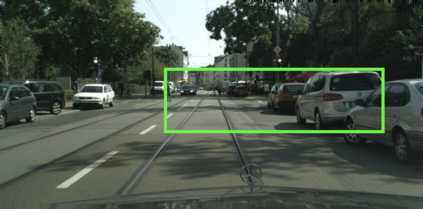
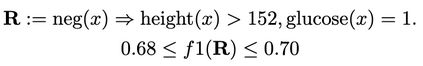Machine learning models can make basic errors that are easily hidden within vast amounts of data. Such errors often run counter to human intuition referred to as "common sense". We thereby seek to characterize common sense for data-driven models, and quantify the extent to which a model has learned common sense. We propose a framework that integrates logic-based methods with statistical inference to derive common sense rules from a model's training data without supervision. We further show how to adapt models at test-time to reduce common sense rule violations and produce more coherent predictions. We evaluate our framework on datasets and models for three different domains. It generates around 250 to 300k rules over these datasets, and uncovers 1.5k to 26k violations of those rules by state-of-the-art models for the respective datasets. Test-time adaptation reduces these violations by up to 38% without impacting overall model accuracy.
翻译:机器学习模型可以产生基本错误,这些错误很容易隐藏在大量数据中。这些错误常常与被称为“常识”的人类直觉相悖。 因此,我们试图将数据驱动模型的常识定性为数据驱动模型的常识,并量化模型学到常识的程度。 我们提出了一个框架,将逻辑方法与统计推理相结合,以便从模型的培训数据中得出常识规则而不受监督。 我们进一步展示了如何在测试时调整模型,以减少常识规则的违反,并产生更一致的预测。 我们评估了我们关于三个不同域的数据集和模型的框架。 它在这些数据集上产生了约250至300公里的规则,并揭示了每个数据集最先进的模型对规则的1.5k至26k的违反情况。 测试时间适应将这些违规率降低到38%,而不影响整个模型的准确性。</s>