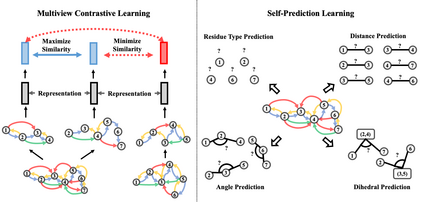
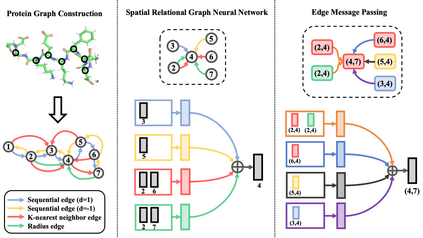
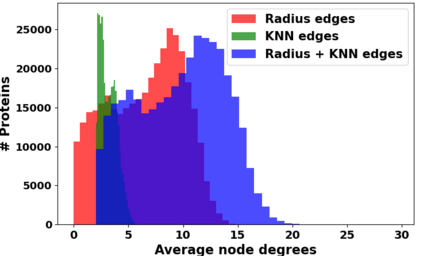
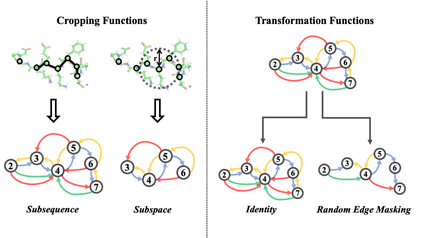
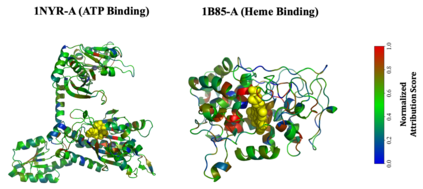
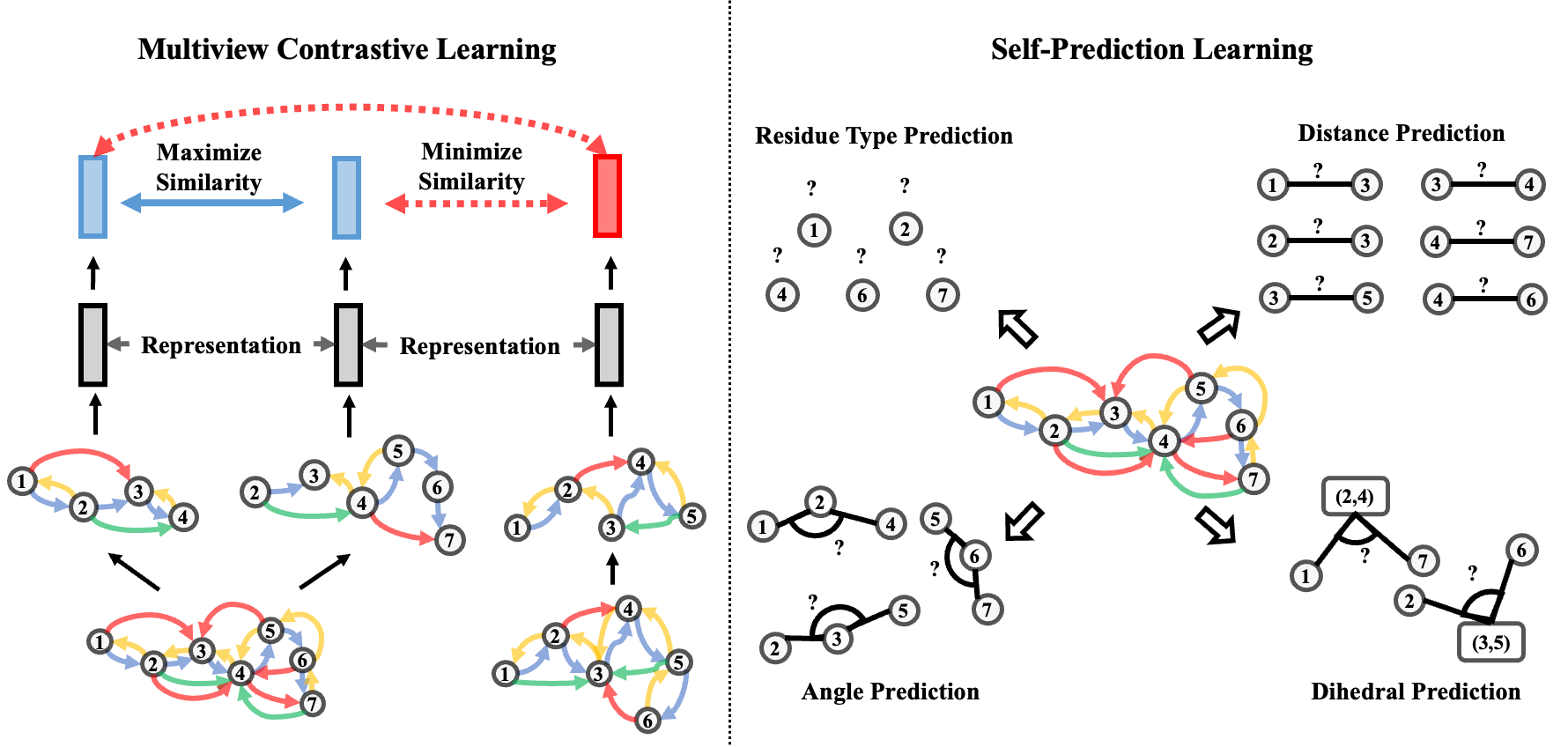
Learning effective protein representations is critical in a variety of tasks in biology such as predicting protein function or structure. Existing approaches usually pretrain protein language models on a large number of unlabeled amino acid sequences and then finetune the models with some labeled data in downstream tasks. Despite the effectiveness of sequence-based approaches, the power of pretraining on known protein structures, which are available in smaller numbers only, has not been explored for protein property prediction, though protein structures are known to be determinants of protein function. In this paper, we propose to pretrain protein representations according to their 3D structures. We first present a simple yet effective encoder to learn the geometric features of a protein. We pretrain the protein graph encoder by leveraging multiview contrastive learning and different self-prediction tasks. Experimental results on both function prediction and fold classification tasks show that our proposed pretraining methods outperform or are on par with the state-of-the-art sequence-based methods, while using much less data. All codes and models will be published upon acceptance.
翻译:在生物学的各种任务中,例如预测蛋白质功能或结构,学习有效的蛋白质表现对于预测蛋白质功能或结构等各种任务至关重要。现有的方法通常是对大量未贴标签的氨基酸序列进行蛋白预演蛋白语言模型,然后用下游任务的一些标签数据对模型进行微调。尽管基于序列的方法具有效力,但在蛋白质属性预测方面尚未探讨对已知蛋白质结构进行预培训的权力,尽管已知蛋白质结构是蛋白质功能的决定因素。在本文中,我们提议根据蛋白质蛋白质的3D结构进行预演。我们首先提出一个简单而有效的编码器,以学习蛋白质的几何特征。我们通过利用多视角对比学习和不同的自我定位任务对蛋白图进行预演。功能预测和折叠分类任务的实验结果显示,我们拟议的培训前方法已经超过或接近于基于最新顺序的方法,同时使用更少的数据。所有代码和模型将在接受后公布。