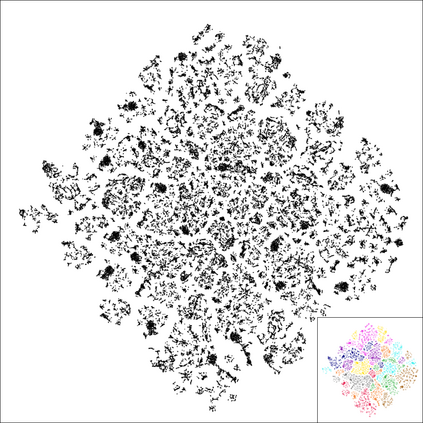
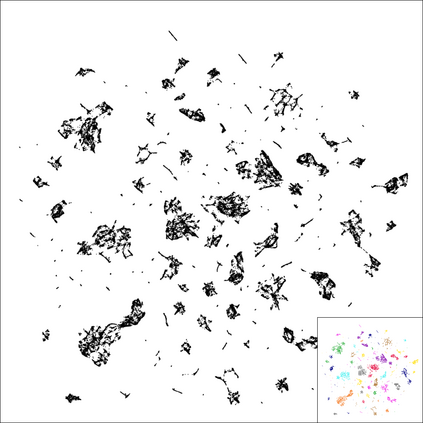
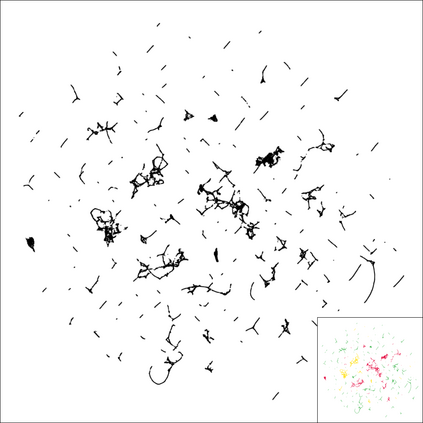
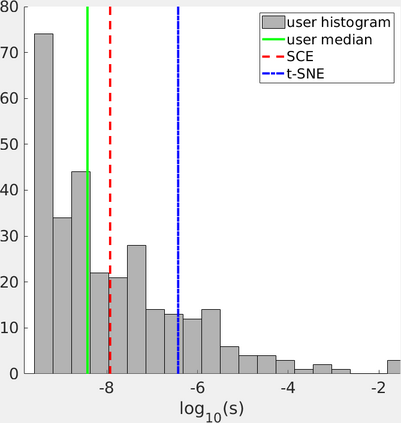
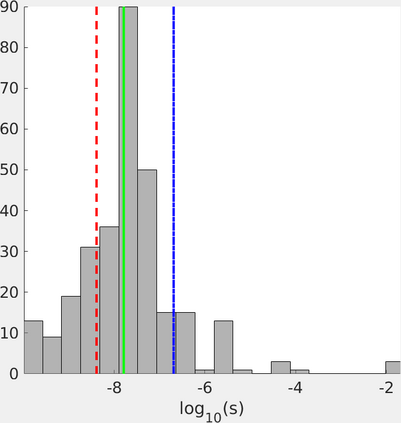
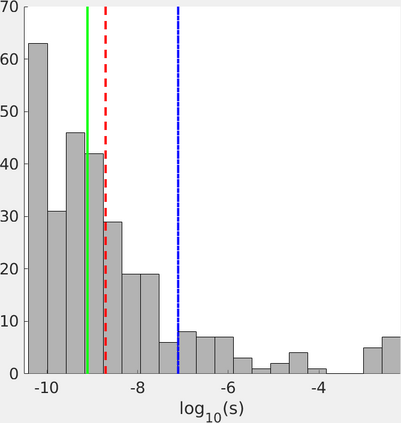
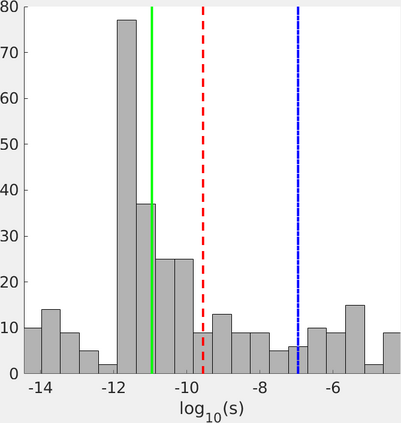
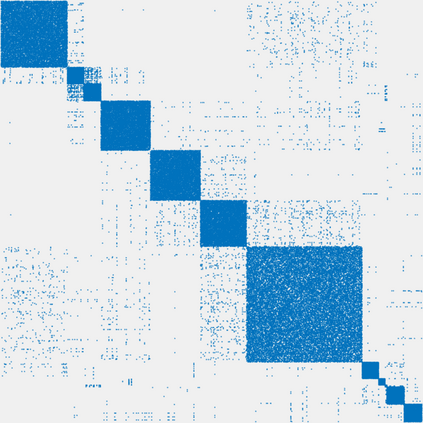
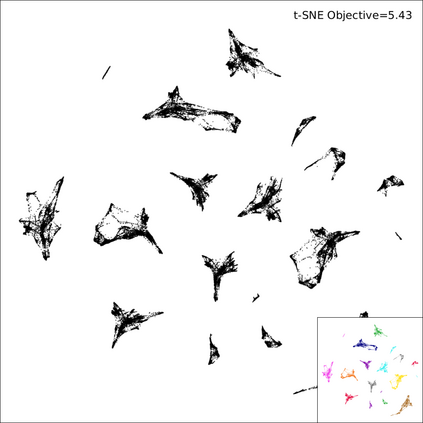
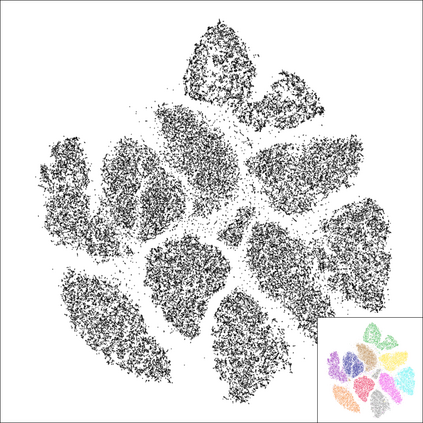
Neighbor Embedding (NE) aims to preserve pairwise similarities between data items and has been shown to yield an effective principle for data visualization. However, even the best existing NE methods such as Stochastic Neighbor Embedding (SNE) may leave large-scale patterns hidden, for example clusters, despite strong signals being present in the data. To address this, we propose a new cluster visualization method based on the Neighbor Embedding principle. We first present a family of Neighbor Embedding methods that generalizes SNE by using non-normalized Kullback-Leibler divergence with a scale parameter. In this family, much better cluster visualizations often appear with a parameter value different from the one corresponding to SNE. We also develop an efficient software that employs asynchronous stochastic block coordinate descent to optimize the new family of objective functions. Our experimental results demonstrate that the method consistently and substantially improves the visualization of data clusters compared with the state-of-the-art NE approaches.
翻译:邻里嵌入式(NE)旨在维护数据项目之间的对等相似性,并显示它能产生数据可视化的有效原则。然而,即使现有的最佳NE方法,如Stochatic 邻里嵌入式(SNE),也可能会隐藏大型模式,例如集群,尽管数据中存在强烈信号。为此,我们根据邻里嵌入式原则提出一个新的集群可视化方法。我们首先提出邻里嵌入式方法,采用非正常的 Kullback- Leibeller 参数,将 SNE 普遍化。在这个大家庭中,更好的集群可视化方法往往呈现出与SNE对应的参数值不同的参数值。我们还开发了一种高效软件,使用无同步的吸取式块来协调血统,以优化目标功能的新组合。我们的实验结果表明,该方法与最先进的NE方法相比,一致和大幅度地改进了数据集群的可视化。