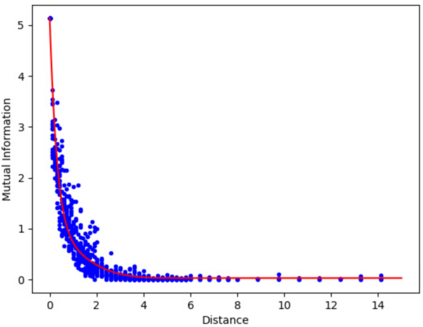
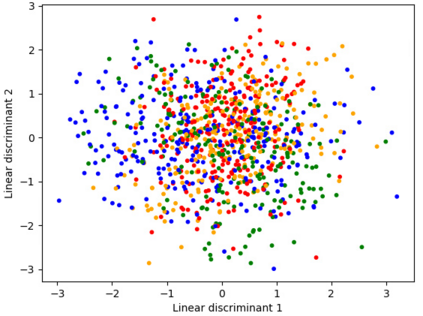
Classification algorithms have recently found applications in computational physics for the selection of numerical methods or models adapted to the environment and the state of the physical system. For such classification tasks, labeled training data come from numerical simulations and generally correspond to physical fields discretized on a mesh. Three challenging difficulties arise: the lack of training data, their high dimensionality, and the non-applicability of common data augmentation techniques to physics data. This article introduces two algorithms to address these issues, one for dimensionality reduction via feature selection, and one for data augmentation. These algorithms are combined with a wide variety of classifiers for their evaluation. When combined with a stacking ensemble made of six multilayer perceptrons and a ridge logistic regression, they enable reaching an accuracy of 90% on our classification problem for nonlinear structural mechanics.
翻译:最近,分类算法在计算物理学中找到了用于选择适应环境和物理系统状态的数字方法或模型的应用。对于这种分类任务,标签的培训数据来自数字模拟,一般与网状上分离的物理领域相对应。出现了三个具有挑战性的困难:缺乏培训数据,其高度的维度,以及通用数据增强技术不适用于物理数据。这一条引入了两种用于解决这些问题的算法,一种通过特征选择降低维度,另一种是数据增强。这些算法与各种各样的分类方法相结合,用于评估它们。当它们与由六个多层透视器组成的堆叠组合和一个脊柱后勤回归相结合时,它们能够使非线性结构力学的分类问题达到90%的精确度。