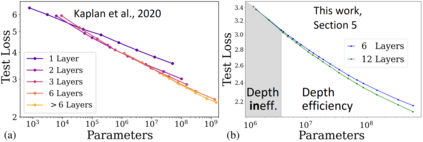
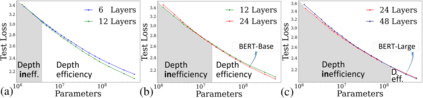
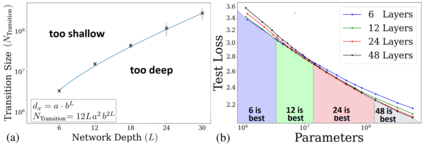
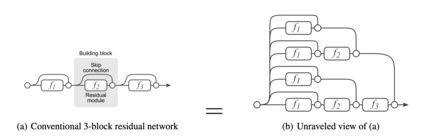
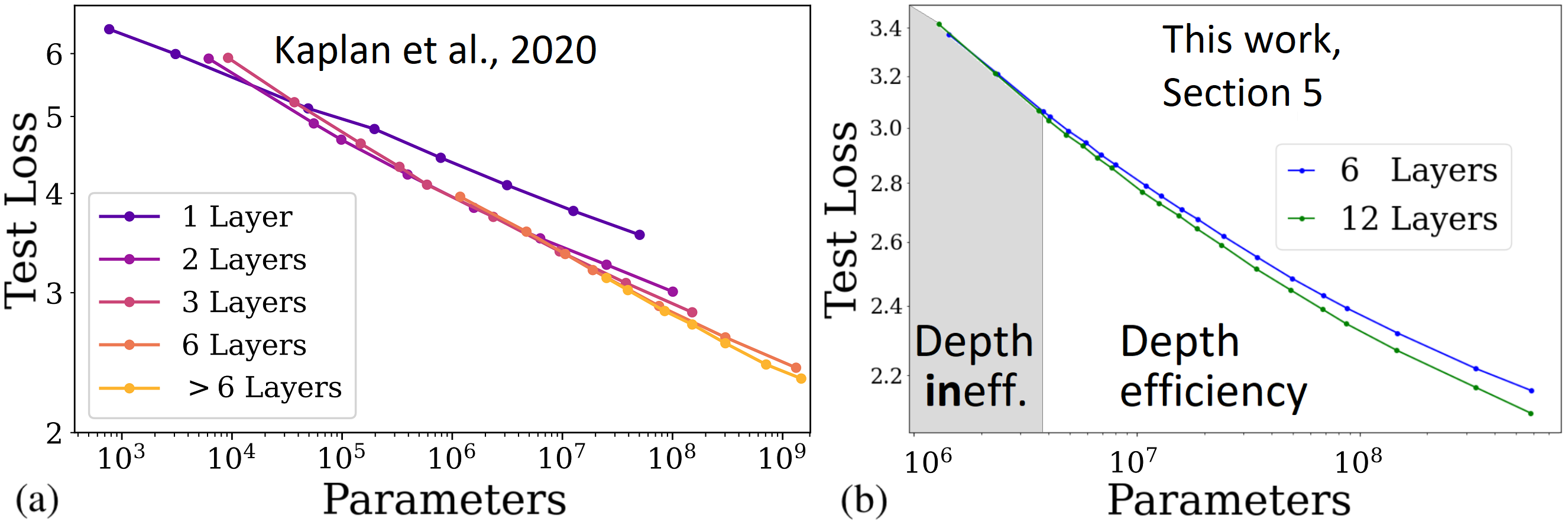
Self-attention architectures, which are rapidly pushing the frontier in natural language processing, demonstrate a surprising depth-inefficient behavior: previous works indicate that increasing the internal representation (network width) is just as useful as increasing the number of self-attention layers (network depth). We theoretically predict a width-dependent transition between depth-efficiency and depth-inefficiency in self-attention. We conduct systematic empirical ablations on networks of depths 6 to 48 that clearly reveal the theoretically predicted behaviors, and provide explicit quantitative suggestions regarding the optimal depth-to-width allocation for a given self-attention network size. The race towards beyond 1-Trillion parameter language models renders informed guidelines for increasing self-attention depth and width in tandem an essential ingredient. Our guidelines elucidate the depth-to-width trade-off in self-attention networks of sizes up to the scale of GPT3 (which is too deep for its size), and beyond, marking an unprecedented width of 30K as optimal for a 1-Trillion parameter self-attention network.
翻译:快速推进自然语言处理前沿的自留结构展示出一种令人惊讶的深度低效率行为:先前的工程表明,增加内部代表(网络宽度)与增加自留层(网络深度)一样有用。我们理论上预测,在深度效率和深度低效率之间会有宽度的过渡,从深度效率到自留自留的深度低效率。我们对深度网络6至48进行系统的经验总结,清楚显示理论上预测的行为,并就特定自留网络规模的最佳深度至宽度分配提供明确的量化建议。 超越一三千参数语言模型的竞赛为增加自留深度和宽度提供了知情的指导方针,将一个基本要素连在一起。我们的指导方针阐明了自留规模网络的深度至两边交换,其规模达到GPT3(其规模太深),超出全球PT3(其规模),标志着一个自留参数自留网络的前所未有的最佳宽度为30K。