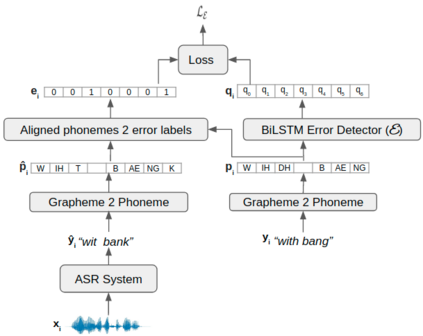
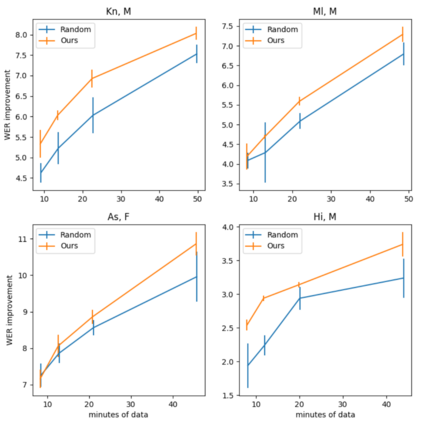
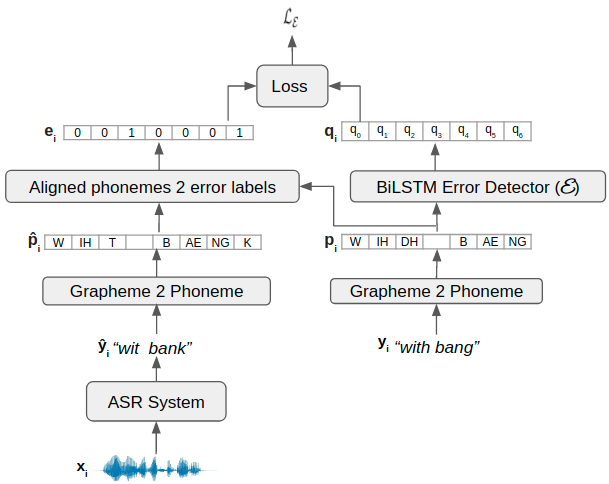
We consider the task of personalizing ASR models while being constrained by a fixed budget on recording speaker-specific utterances. Given a speaker and an ASR model, we propose a method of identifying sentences for which the speaker's utterances are likely to be harder for the given ASR model to recognize. We assume a tiny amount of speaker-specific data to learn phoneme-level error models which help us select such sentences. We show that speaker's utterances on the sentences selected using our error model indeed have larger error rates when compared to speaker's utterances on randomly selected sentences. We find that fine-tuning the ASR model on the sentence utterances selected with the help of error models yield higher WER improvements in comparison to fine-tuning on an equal number of randomly selected sentence utterances. Thus, our method provides an efficient way of collecting speaker utterances under budget constraints for personalizing ASR models.
翻译:我们考虑将ASR模式个性化的任务,同时受记录特定发言者发言的固定预算限制。根据一个发言者和一个ASR模式,我们建议一种方法,确定发言者发言可能较难被特定ASR模式识别的句子。我们假定了少量针对发言者的数据,以学习有助于我们选择此类句子的语音级错误模式。我们显示,与随机选择的句子的发言者发言相比,使用错误模式选定的句子上的发言确实有较大的错误率。我们发现,在错误模式帮助下,对选定的句子的ASR模式进行微调,与对相同数量的随机选择的句子进行微调相比,与随机选择的句子相比,改进了WER。因此,我们的方法提供了一种有效的方法,在预算限制下收集发言者在个人化ASR模式上的话。