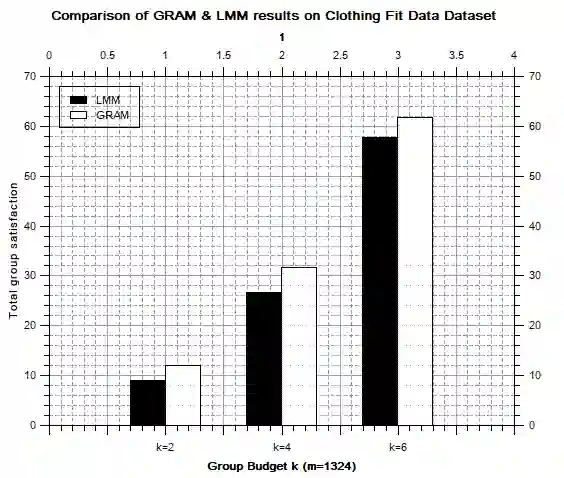
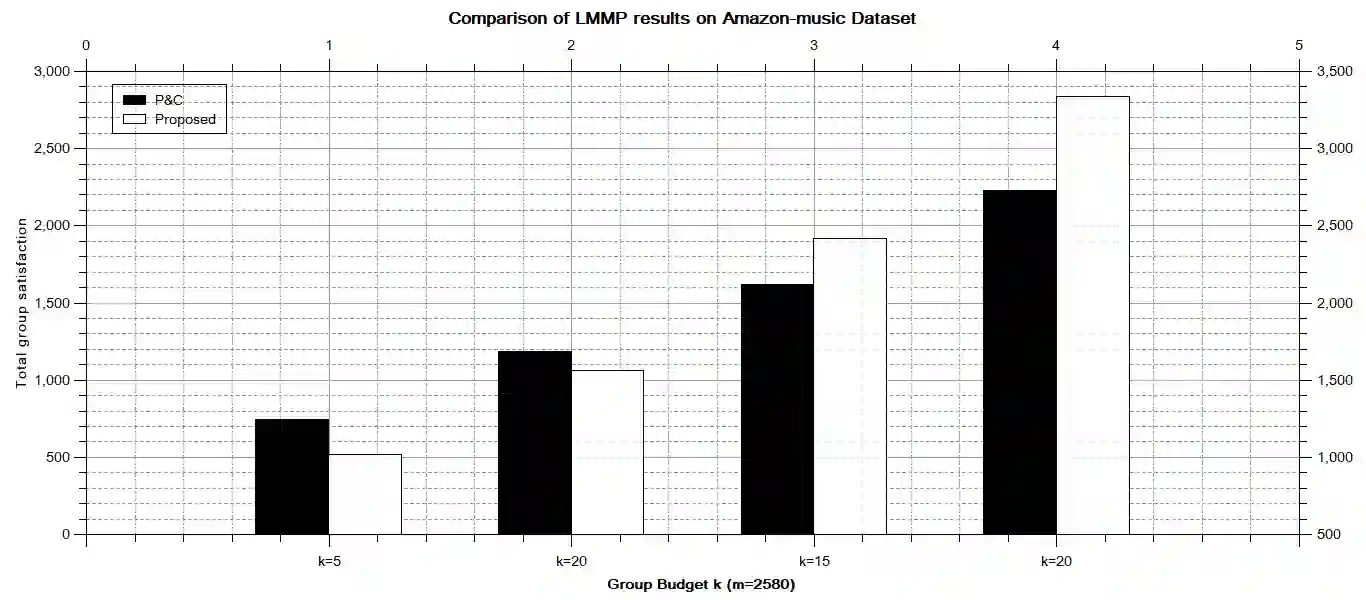
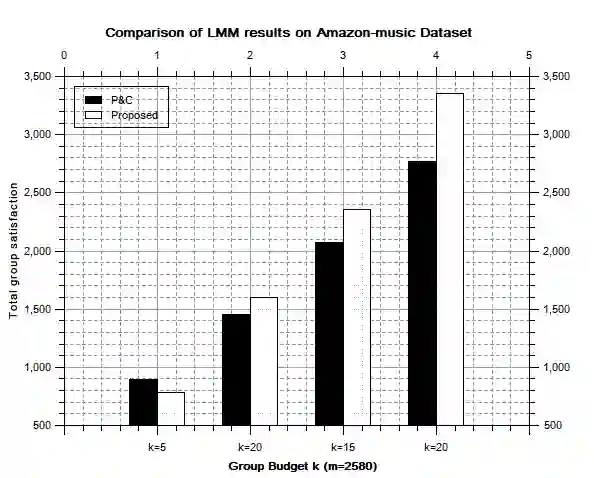
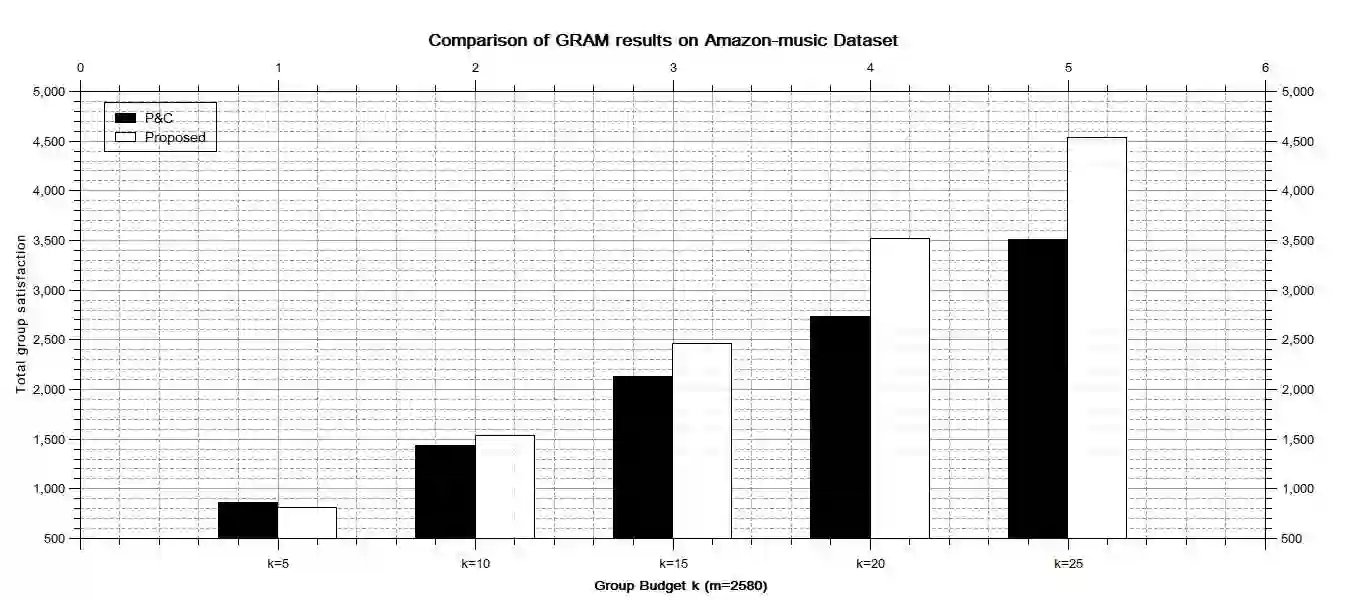
In general, recommender systems are designed to provide personalized items to a user. But in few cases, items are recommended for a group, and the challenge is to aggregate the individual user preferences to infer the recommendation to a group. It is also important to consider the similarity of characteristics among the members of a group to generate a better recommendation. Members of an automatically identified group will have similar characteristics, and reaching a consensus with a decision-making process is preferable in this case. It requires users-items and their rating interactions over a utility matrix to auto-detect the groups in group recommendations. We may not overlook other intrinsic information to form a group. The textual information also plays a pivotal role in user clustering. In this paper, we auto-detect the groups based on the textual similarity of the metadata (review texts). We consider the order in user preferences in our models. We have conducted extensive experiments over two real-world datasets to check the efficacy of the proposed models. We have also conducted a competitive comparison with a baseline model to show the improvements in the quality of recommendations.
翻译:一般来说,建议者系统的设计是为了向用户提供个性化项目。但是,在少数情况下,建议一组项目,挑战在于将单个用户的偏好汇总起来,将建议推给一个组。同样重要的是,要考虑一个组成员特征的相似性,以产生更好的建议。自动确定的组成员具有相似性,在此情况下,最好与决策过程达成共识。它要求用户项目及其在工具矩阵上的评级互动,以自动检测组群建议中的组群。我们可能不忽视其他内在信息来组成一个组群。文本信息在用户群中也起着关键作用。在本文件中,我们根据元数据的文本相似性(审查文本)自动检测组。我们按用户偏好的模式来考虑这些组群的顺序。我们对两个真实世界数据集进行了广泛的试验,以检查拟议模型的功效。我们还与一个基线模型进行了竞争性比较,以显示建议质量的改进。