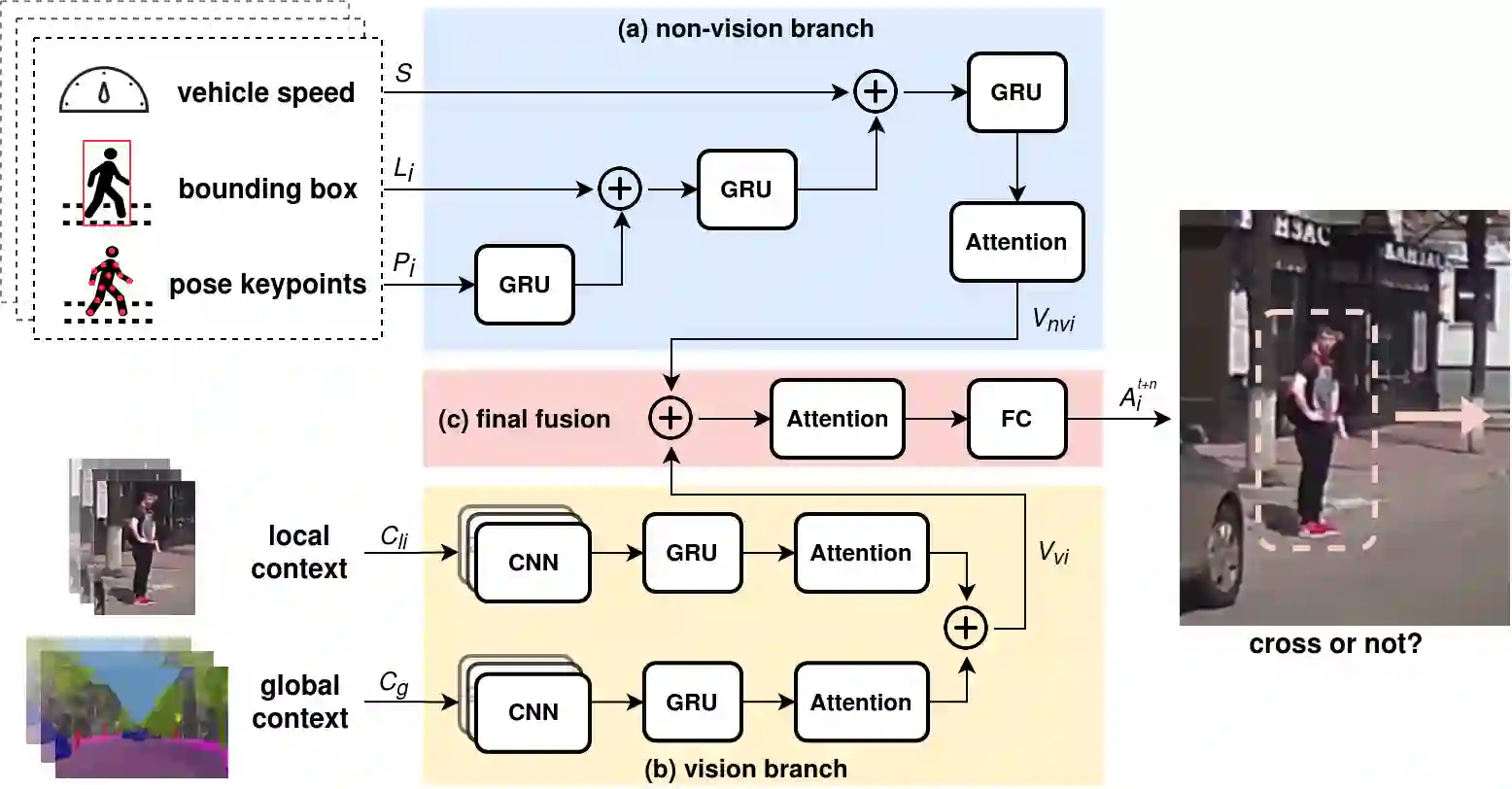
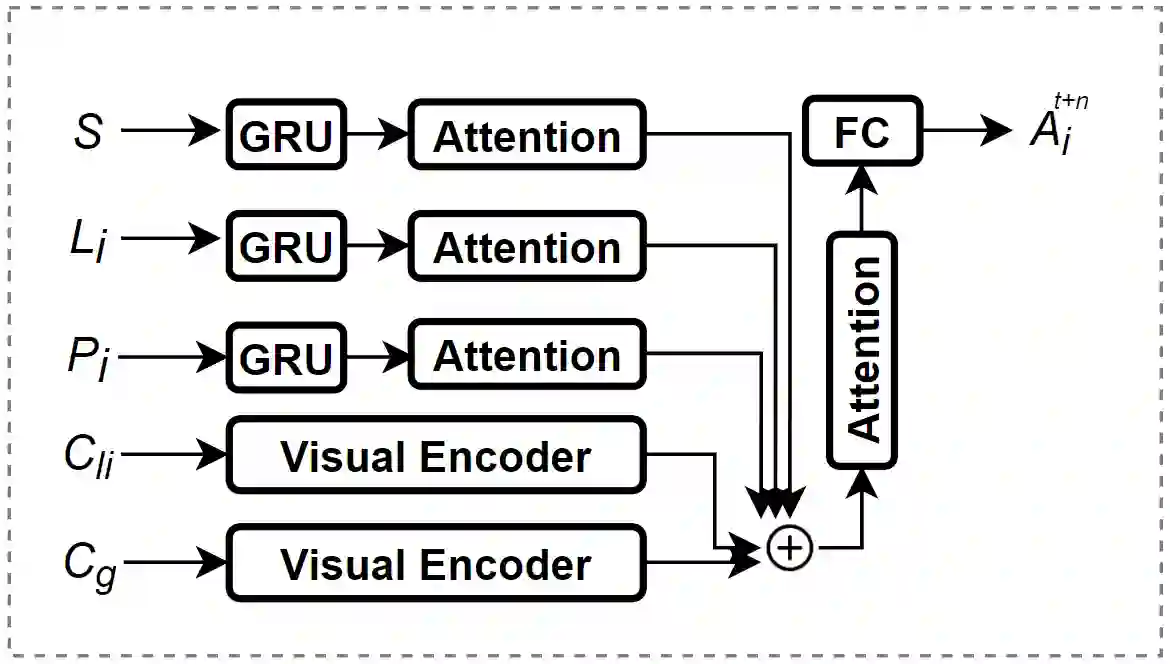
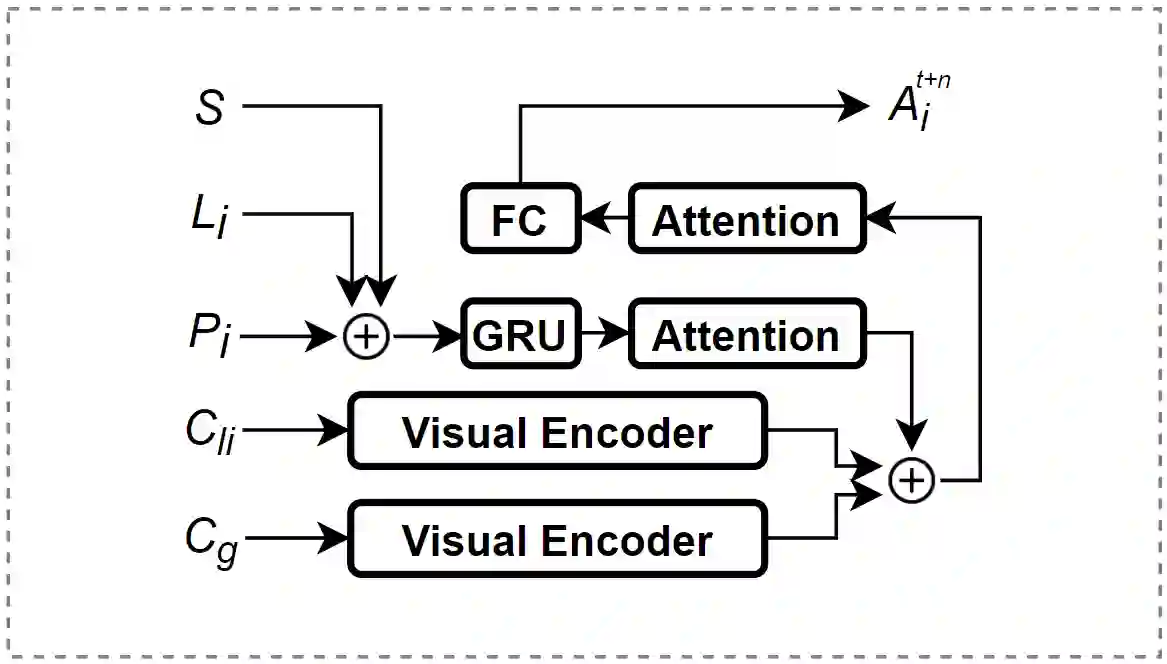
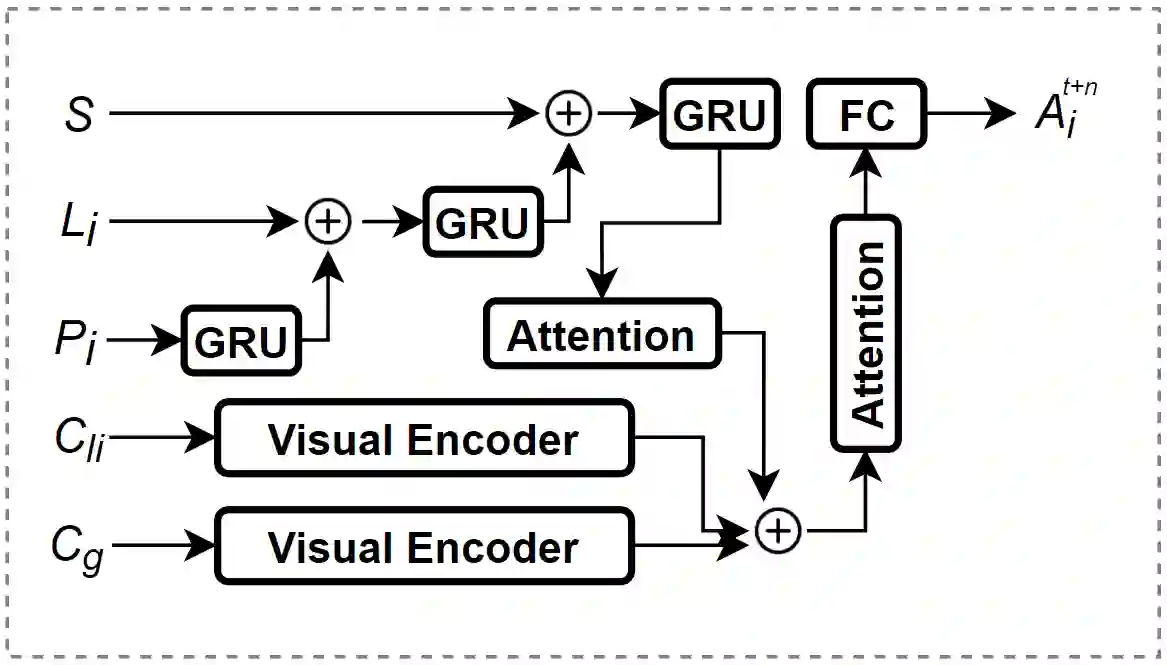
Predicting vulnerable road user behavior is an essential prerequisite for deploying Automated Driving Systems (ADS) in the real-world. Pedestrian crossing intention should be recognized in real-time, especially for urban driving. Recent works have shown the potential of using vision-based deep neural network models for this task. However, these models are not robust and certain issues still need to be resolved. First, the global spatio-temproal context that accounts for the interaction between the target pedestrian and the scene has not been properly utilized. Second, the optimum strategy for fusing different sensor data has not been thoroughly investigated. This work addresses the above limitations by introducing a novel neural network architecture to fuse inherently different spatio-temporal features for pedestrian crossing intention prediction. We fuse different phenomena such as sequences of RGB imagery, semantic segmentation masks, and ego-vehicle speed in an optimum way using attention mechanisms and a stack of recurrent neural networks. The optimum architecture was obtained through exhaustive ablation and comparison studies. Extensive comparative experiments on the JAAD pedestrian action prediction benchmark demonstrate the effectiveness of the proposed method, where state-of-the-art performance was achieved. Our code is open-source and publicly available.
翻译:在现实世界中部署自动驾驶系统(ADS)的基本先决条件是,预测道路使用者的脆弱行为是真实世界中部署自动驾驶系统(ADS)的基本先决条件。应当实时地承认Pedestrian过境点的意图,特别是城市驾驶。最近的工作表明,有可能为此任务使用基于视觉的深神经网络模型。然而,这些模型并不健全,某些问题仍需要解决。首先,用于目标行人和场景之间相互作用的全球脉冲-脉冲-脉冲-脉冲-脉冲-脉冲-脉冲-脉冲-脉冲-脉冲-行人/行人/行人/行人/行人/行人/行人/行人/行人/行人/行人/行人/行人/行人/行人/行人/行人/行人/行车/行车/行车/行车/行车/行车/行车/行车/行车/行车/行车/行车/行车/行车/行车/行车/行车/行车/行车/行车/行车/行车/行车/行车/行车/行车/行车/行车/行车/行车/行车/行车/行车/行车/行车/行车/行车/行车/行车/行车/行车/行车/行车/行车/行车/行车/行车/行车/行车/行车/行车/行车/行车/行车/行车/行车/行车/行车/行车/行车/行车/行车/行车/行车/行车/行车/行车/行车/行车/行车/行车/行车/行车/行车/行车/行车/行车/行车/行车///行车/行车/行车/行车/行车/行车/行车/行车/行车/行车/行/行/行车/行车/行车/行车/行车/行/行车/行车/行车/行车/行车/行车/行车/行车/行车/行车/行车/行车/行车/行