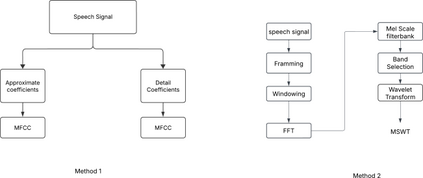
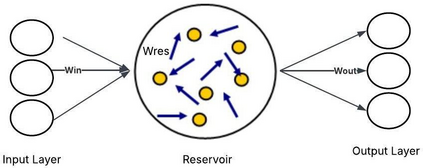
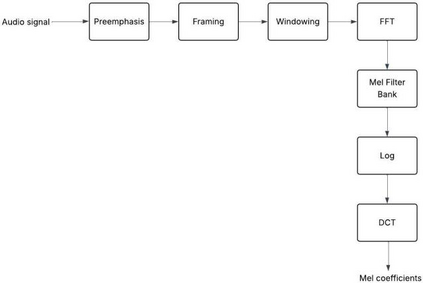
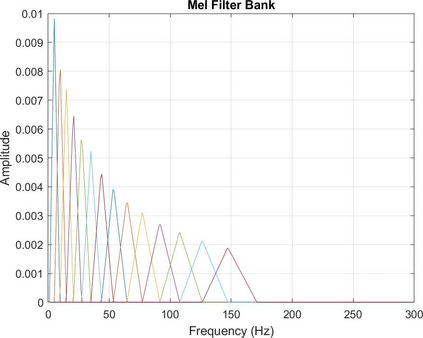
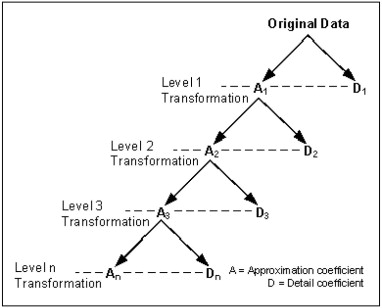
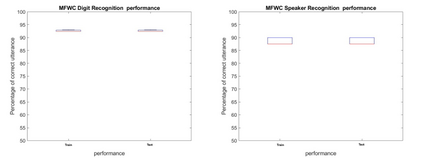
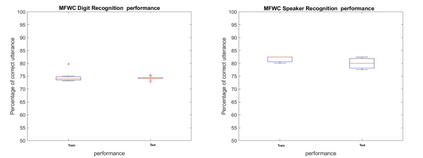
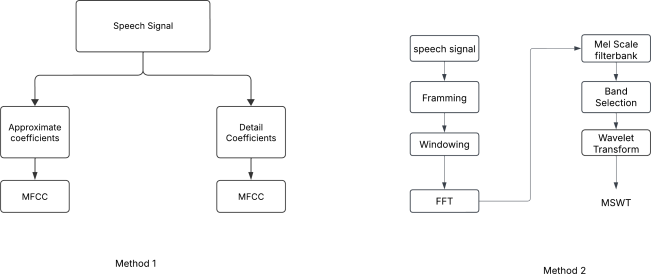
Extracting features from the speech is the most critical process in speech signal processing. Mel Frequency Cepstral Coefficients (MFCC) are the most widely used features in the majority of the speaker and speech recognition applications, as the filtering in this feature is similar to the filtering taking place in the human ear. But the main drawback of this feature is that it provides only the frequency information of the signal but does not provide the information about at what time which frequency is present. The wavelet transform, with its flexible time-frequency window, provides time and frequency information of the signal and is an appropriate tool for the analysis of non-stationary signals like speech. On the other hand, because of its uniform frequency scaling, a typical wavelet transform may be less effective in analysing speech signals, have poorer frequency resolution in low frequencies, and be less in line with human auditory perception. Hence, it is necessary to develop a feature that incorporates the merits of both MFCC and wavelet transform. A great deal of studies are trying to combine both these features. The present Wavelet Transform based Mel-scaled feature extraction methods require more computation when a wavelet transform is applied on top of Mel-scale filtering, since it adds extra processing steps. Here we are proposing a method to extract Mel scale features in time domain combining the concept of wavelet transform, thus reducing the computational burden of time-frequency conversion and the complexity of wavelet extraction. Combining our proposed Time domain Mel frequency Wavelet Coefficient(TMFWC) technique with the reservoir computing methodology has significantly improved the efficiency of audio signal processing.
翻译:暂无翻译