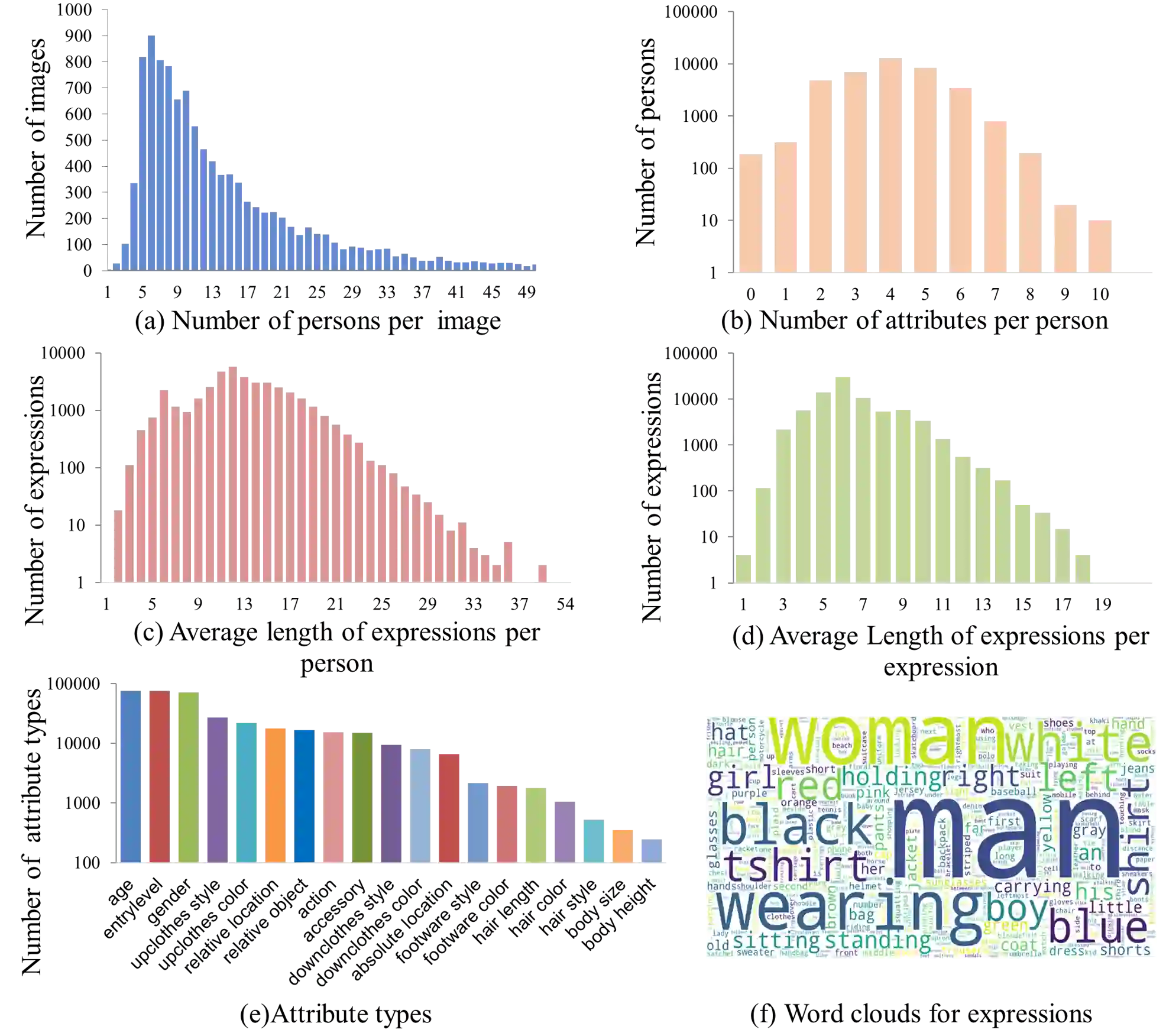
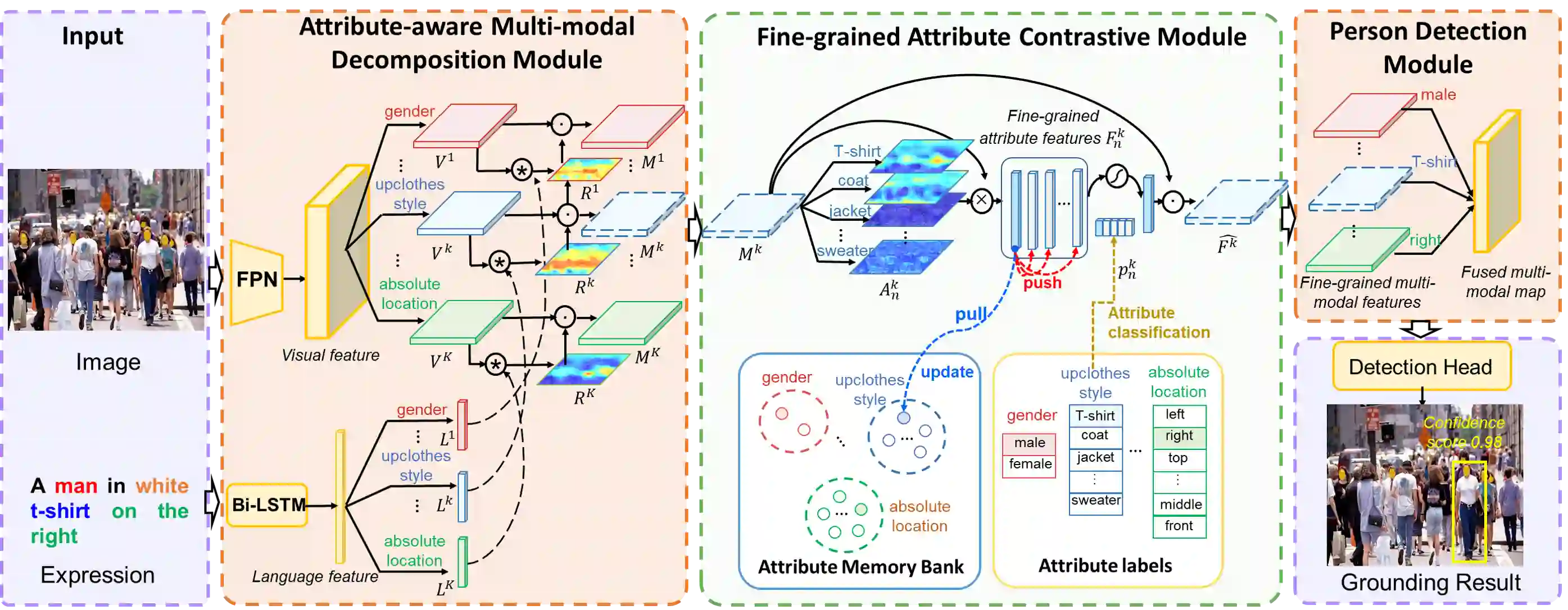
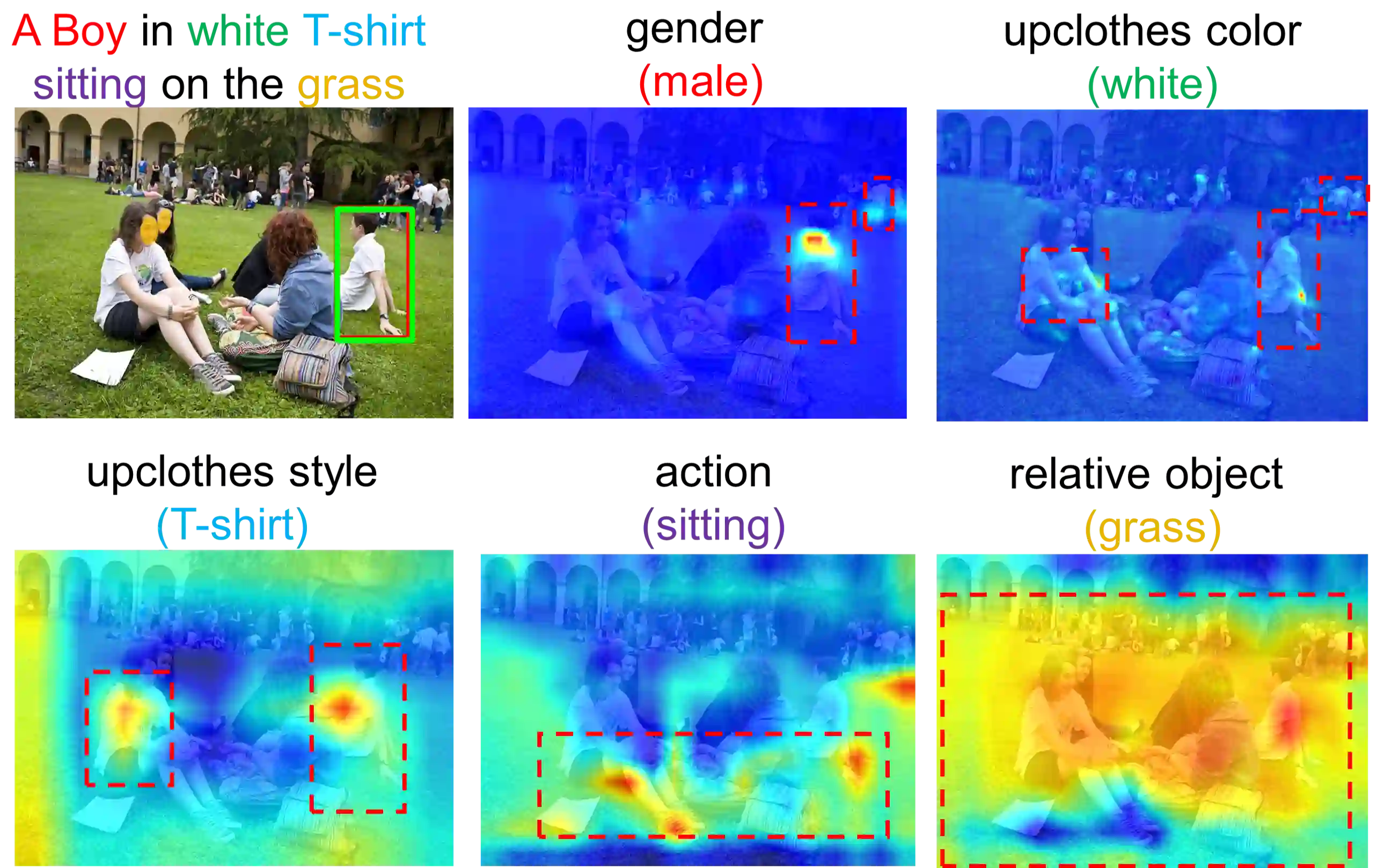
Crowd understanding has aroused the widespread interest in vision domain due to its important practical significance. Unfortunately, there is no effort to explore crowd understanding in multi-modal domain that bridges natural language and computer vision. Referring expression comprehension (REF) is such a representative multi-modal task. Current REF studies focus more on grounding the target object from multiple distinctive categories in general scenarios. It is difficult to applied to complex real-world crowd understanding. To fill this gap, we propose a new challenging dataset, called RefCrowd, which towards looking for the target person in crowd with referring expressions. It not only requires to sufficiently mine the natural language information, but also requires to carefully focus on subtle differences between the target and a crowd of persons with similar appearance, so as to realize the fine-grained mapping from language to vision. Furthermore, we propose a Fine-grained Multi-modal Attribute Contrastive Network (FMAC) to deal with REF in crowd understanding. It first decomposes the intricate visual and language features into attribute-aware multi-modal features, and then captures discriminative but robustness fine-grained attribute features to effectively distinguish these subtle differences between similar persons. The proposed method outperforms existing state-of-the-art (SoTA) methods on our RefCrowd dataset and existing REF datasets. In addition, we implement an end-to-end REF toolbox for the deeper research in multi-modal domain. Our dataset and code can be available at: \url{https://qiuheqian.github.io/datasets/refcrowd/}.
翻译:众人理解已引起人们对视觉领域的广泛兴趣, 因为它具有重要的实际意义。 不幸的是, 没有努力探索多模式领域的人群理解, 以连接自然语言和计算机视觉。 引用表达理解( REF) 是一个具有代表性的多模式任务。 当前 REF 研究更侧重于在一般情况下将目标对象从多种不同类别定位为地面; 难以应用于复杂的现实世界人群理解。 为了填补这一空白, 我们提议一个新的具有挑战性的数据集, 名为 RefCrowd, 用于在人群中寻找显示表达表达方式的对象。 它不仅需要充分挖掘自然语言信息, 还需要仔细关注目标与类似外观人群之间的微妙差异, 以便实现从语言到视觉的细微绘图。 此外, 我们提议了一个精细的多模式匹配网络。 首先, 将复杂的视觉和语言特性转换成属性- 多种模式特征, 然后捕捉具有歧视性但坚固的深层次语言信息信息信息, 并且将我们现有的精确的当前数据格式/ 将我们现有的精确的当前数据方法转化为。