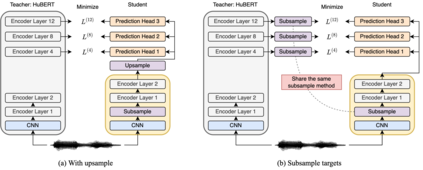
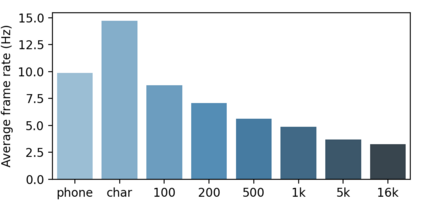
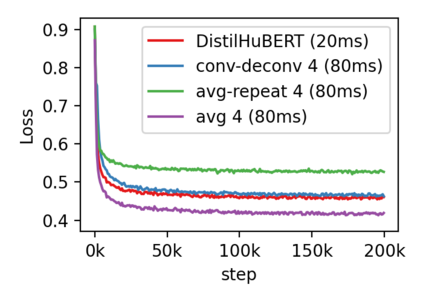
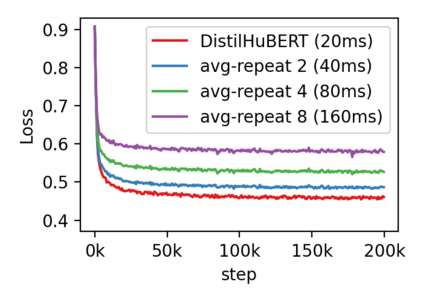
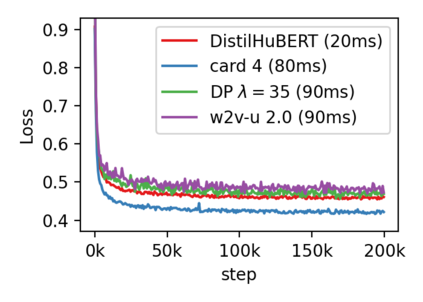
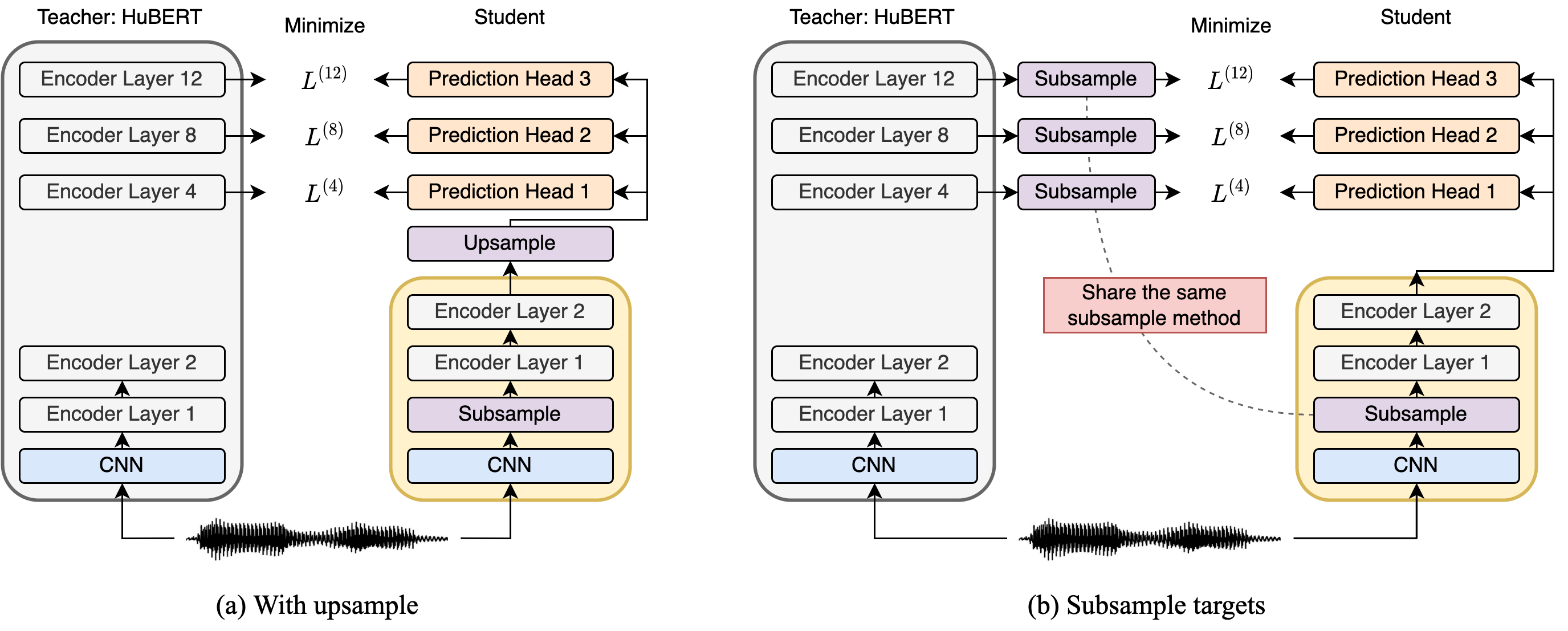
Compressing self-supervised models has become increasingly necessary, as self-supervised models become larger. While previous approaches have primarily focused on compressing the model size, shortening sequences is also effective in reducing the computational cost. In this work, we study fixed-length and variable-length subsampling along the time axis in self-supervised learning. We explore how individual downstream tasks are sensitive to input frame rates. Subsampling while training self-supervised models not only improves the overall performance on downstream tasks under certain frame rates, but also brings significant speed-up in inference. Variable-length subsampling performs particularly well under low frame rates. In addition, if we have access to phonetic boundaries, we find no degradation in performance for an average frame rate as low as 10 Hz.
翻译:随着自我监督模式的扩大,压缩自我监督模式变得日益必要。虽然以前的做法主要侧重于压缩模型规模,但缩短序列对于降低计算成本也十分有效。在这项工作中,我们研究在自我监督学习的时间轴上沿时间轴进行固定长和多长的子抽样;我们探索单个下游任务如何对输入框架率敏感。在培训自我监督模式的同时,抽样不仅改进了某些框架费率下下下游任务的总体绩效,而且还带来了显著的加速推论。在低框架费率下,变量次抽样尤其表现良好。此外,如果我们能够进入语音边界,我们发现平均框架费率的性能不会降低至10赫兹。