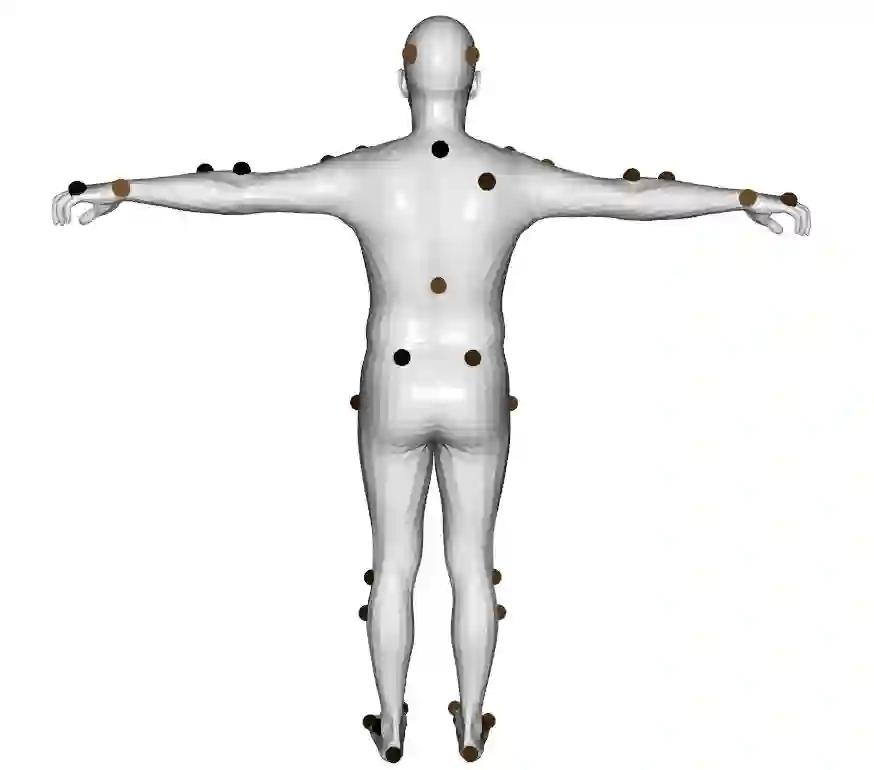
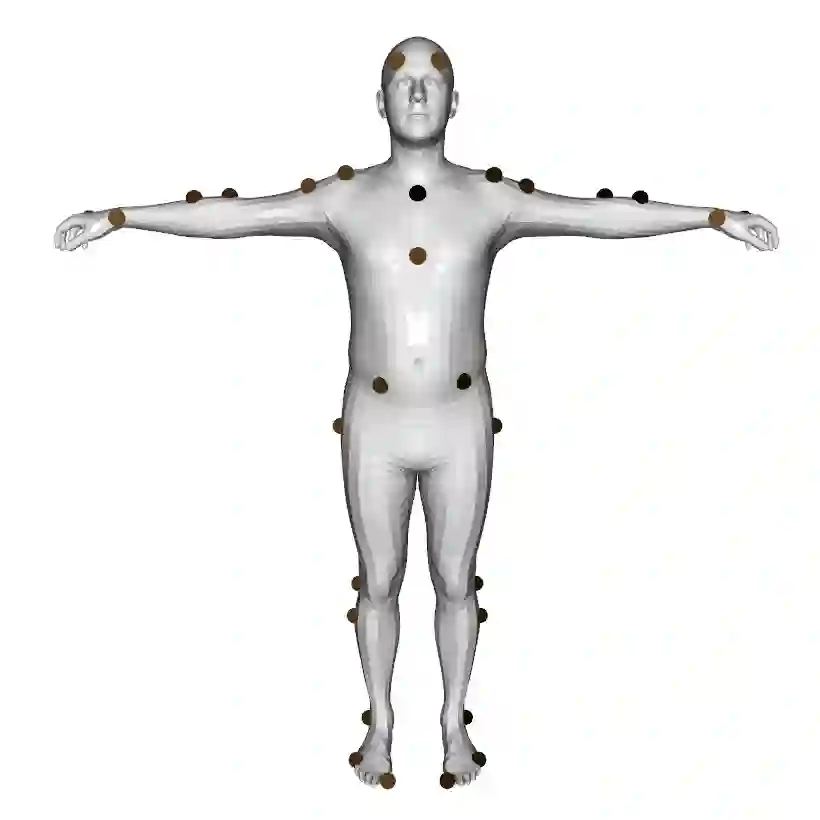
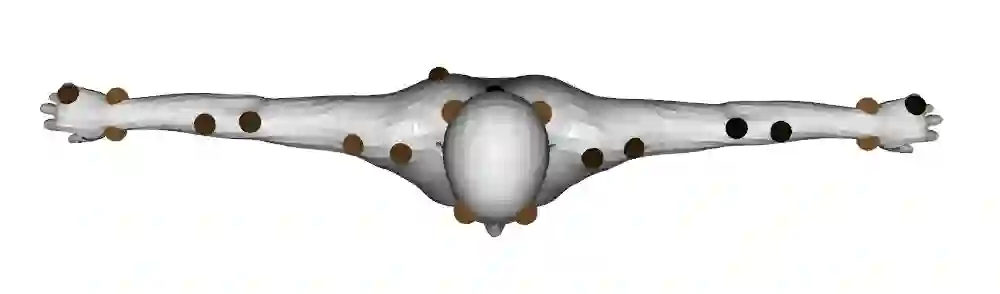
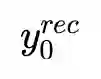A key step towards understanding human behavior is the prediction of 3D human motion. Successful solutions have many applications in human tracking, HCI, and graphics. Most previous work focuses on predicting a time series of future 3D joint locations given a sequence 3D joints from the past. This Euclidean formulation generally works better than predicting pose in terms of joint rotations. Body joint locations, however, do not fully constrain 3D human pose, leaving degrees of freedom undefined, making it hard to animate a realistic human from only the joints. Note that the 3D joints can be viewed as a sparse point cloud. Thus the problem of human motion prediction can be seen as point cloud prediction. With this observation, we instead predict a sparse set of locations on the body surface that correspond to motion capture markers. Given such markers, we fit a parametric body model to recover the 3D shape and pose of the person. These sparse surface markers also carry detailed information about human movement that is not present in the joints, increasing the naturalness of the predicted motions. Using the AMASS dataset, we train MOJO, which is a novel variational autoencoder that generates motions from latent frequencies. MOJO preserves the full temporal resolution of the input motion, and sampling from the latent frequencies explicitly introduces high-frequency components into the generated motion. We note that motion prediction methods accumulate errors over time, resulting in joints or markers that diverge from true human bodies. To address this, we fit SMPL-X to the predictions at each time step, projecting the solution back onto the space of valid bodies. These valid markers are then propagated in time. Experiments show that our method produces state-of-the-art results and realistic 3D body animations. The code for research purposes is at https://yz-cnsdqz.github.io/MOJO/MOJO.html
翻译:理解人类行为的关键步骤是 3D 人类运动的预测。 成功的解决方案在人类追踪、 HCI 和图形中有许多应用。 大多数先前的工作都侧重于预测未来 3D 联合地点的时间序列 3D 联合地点的顺序 3D 过去的一个 3D 联合点的序列 。 这个 Euclidean 配方通常比 联合旋转 的组合效果要好。 但是, 身体联合位置并不完全限制 3D 人类的外形, 使得自由的程度不那么明确, 使得现实的人很难从联合点中产生。 注意3D 联合点可以被视为一个稀薄的云云。 因此, 人类运动预测的问题可以被看作是点云的预测。 有了这样的观察, 我们反而预测了身体表面上一个稀少的一组位置, 与运动标志相匹配3D 的外形和外形。 这些稀薄的表面标记还包含关于人类运动运动运动的详尽信息, 我们用AMASS 数据集, MOJO 将真实的流- 数据序列 数据序列 数据输出到运动的轨道 机尾部 。