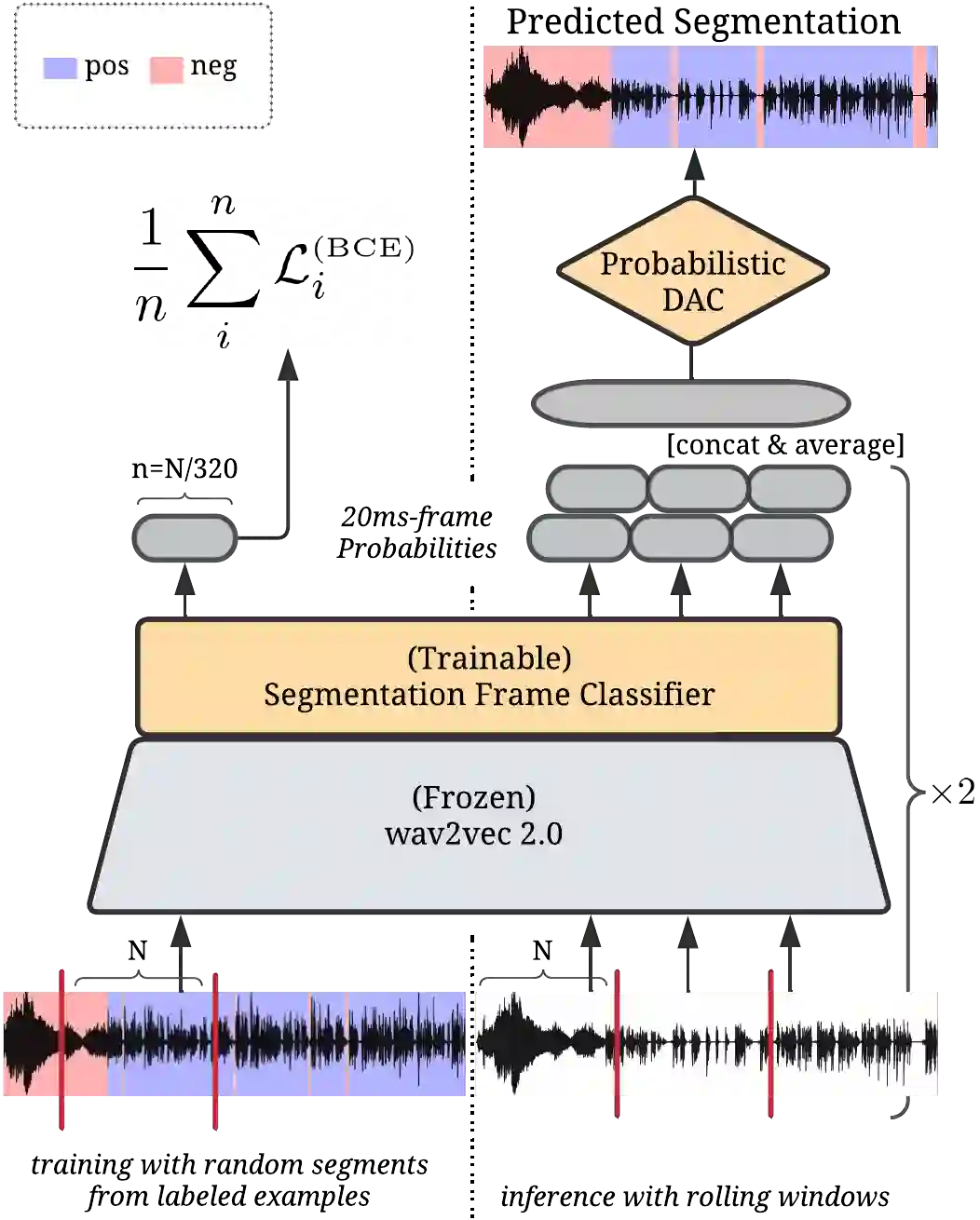
Speech translation models are unable to directly process long audios, like TED talks, which have to be split into shorter segments. Speech translation datasets provide manual segmentations of the audios, which are not available in real-world scenarios, and existing segmentation methods usually significantly reduce translation quality at inference time. To bridge the gap between the manual segmentation of training and the automatic one at inference, we propose Supervised Hybrid Audio Segmentation (SHAS), a method that can effectively learn the optimal segmentation from any manually segmented speech corpus. First, we train a classifier to identify the included frames in a segmentation, using speech representations from a pre-trained wav2vec 2.0. The optimal splitting points are then found by a probabilistic Divide-and-Conquer algorithm that progressively splits at the frame of lowest probability until all segments are below a pre-specified length. Experiments on MuST-C and mTEDx show that the translation of the segments produced by our method approaches the quality of the manual segmentation on 5 language pairs. Namely, SHAS retains 95-98% of the manual segmentation's BLEU score, compared to the 87-93% of the best existing methods. Our method is additionally generalizable to different domains and achieves high zero-shot performance in unseen languages.
翻译:语音翻译模型无法直接处理长音频,如TED演讲,这些模式必须分成较短的部分。 语音翻译数据集提供音频的人工分解,在现实世界情景中无法提供,而现有的分解方法通常会大大降低推论时间的翻译质量。 为了缩小培训的手工分解与自动分解之间的差距, 我们提议了监督混合音频分解(SHAS), 这种方法可以有效地从任何手动的分解语音中学习最佳分解。 首先, 我们训练了一名分类员, 以便使用预先训练的 wav2vec 2. 0 的语音表达方式来识别包含的分解框架。 然后, 最佳分解点会通过概率分解算法找到最佳分解点, 在所有部分低于预定长度之前, 在最小的概率范围内, 逐步分解。 关于 MuST- C 和 mTEDx 的实验显示, 我们方法制作的各部分的翻译会接近5种语言组合的手工分解质量。 也就是说, SHAS保留了预训练的95-98%的语音分解方法, 将我们现有87- LEU 的高级分解方法比起来, 高级方法将达到最高分解法。