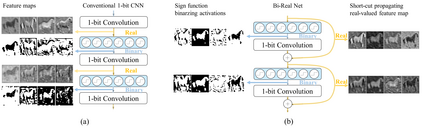
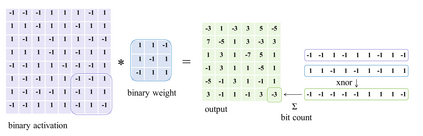
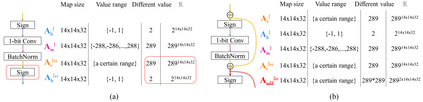
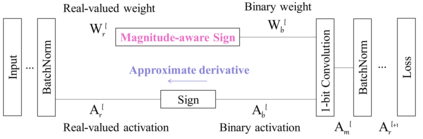
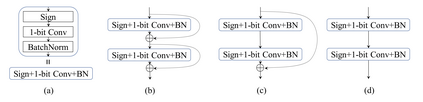
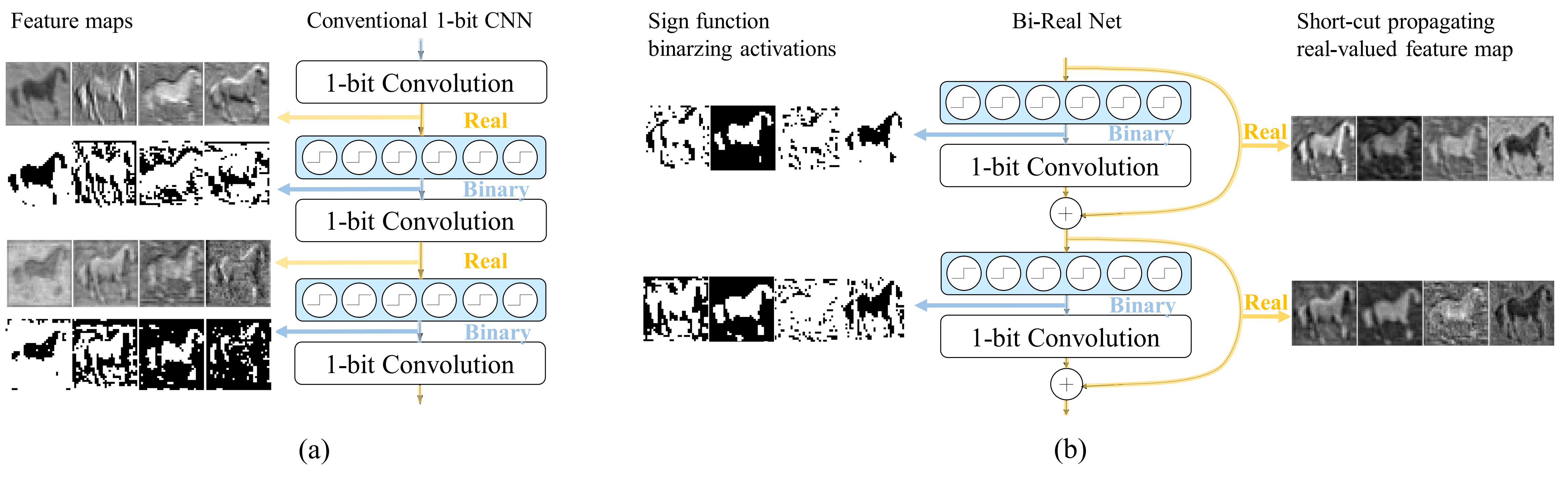
In this work, we study the 1-bit convolutional neural networks (CNNs), of which both the weights and activations are binary. While being efficient, the classification accuracy of the current 1-bit CNNs is much worse compared to their counterpart real-valued CNN models on the large-scale dataset, like ImageNet. To minimize the performance gap between the 1-bit and real-valued CNN models, we propose a novel model, dubbed Bi-Real net, which connects the real activations (after the 1-bit convolution and/or BatchNorm layer, before the sign function) to activations of the consecutive block, through an identity shortcut. Consequently, compared to the standard 1-bit CNN, the representational capability of the Bi-Real net is significantly enhanced and the additional cost on computation is negligible. Moreover, we develop a specific training algorithm including three technical novelties for 1- bit CNNs. Firstly, we derive a tight approximation to the derivative of the non-differentiable sign function with respect to activation. Secondly, we propose a magnitude-aware gradient with respect to the weight for updating the weight parameters. Thirdly, we pre-train the real-valued CNN model with a clip function, rather than the ReLU function, to better initialize the Bi-Real net. Experiments on ImageNet show that the Bi-Real net with the proposed training algorithm achieves 56.4% and 62.2% top-1 accuracy with 18 layers and 34 layers, respectively. Compared to the state-of-the-arts (e.g., XNOR Net), Bi-Real net achieves up to 10% higher top-1 accuracy with more memory saving and lower computational cost.
翻译:在这项工作中,我们研究的是1位平方位的神经神经网络(CNNs),其重量和激活都是二进制的。在效率有效的同时,当前1位的CNN的分类准确性比在大型数据集(如图像网)上的对应的1位平方位和实际估值的CNN模型要差得多。为了尽可能缩小1位平方位和实际估值的CNN模型之间的性能差距,我们提议了一个新模型,称为Bi-RealNet(在信号功能之前的1位平方位平流和(或)BatchNorm层),将真正的激活(在1位平面平面平面上和(或)BatchNorm 平面上)连接到连续的区块的激活。因此,与标准1位CNNPCNN相比,双面网的代表性能力大大提高,而计算的额外成本微乎其微。此外,我们开发了一个具体的培训算法,包括1位CNN的3个技术新版本。首先,我们从一个非可理解的信号功能的衍生物上,更接近。 其次,我们提议在62-直方位上实现18的内值的内值的内值的内值,比重的内值的内值更接近于初始值的内值的内值的内值,比重的内值的内值的内值,比重的内值更重的内值。我们提议。我们提议在初始的内值上,比重。我们提议在前的内值上,比重。