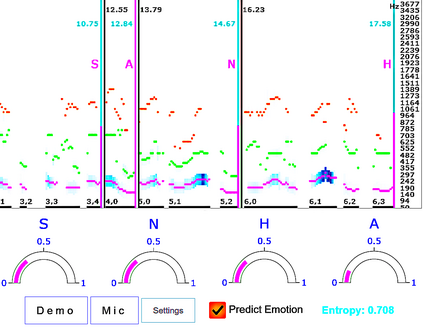
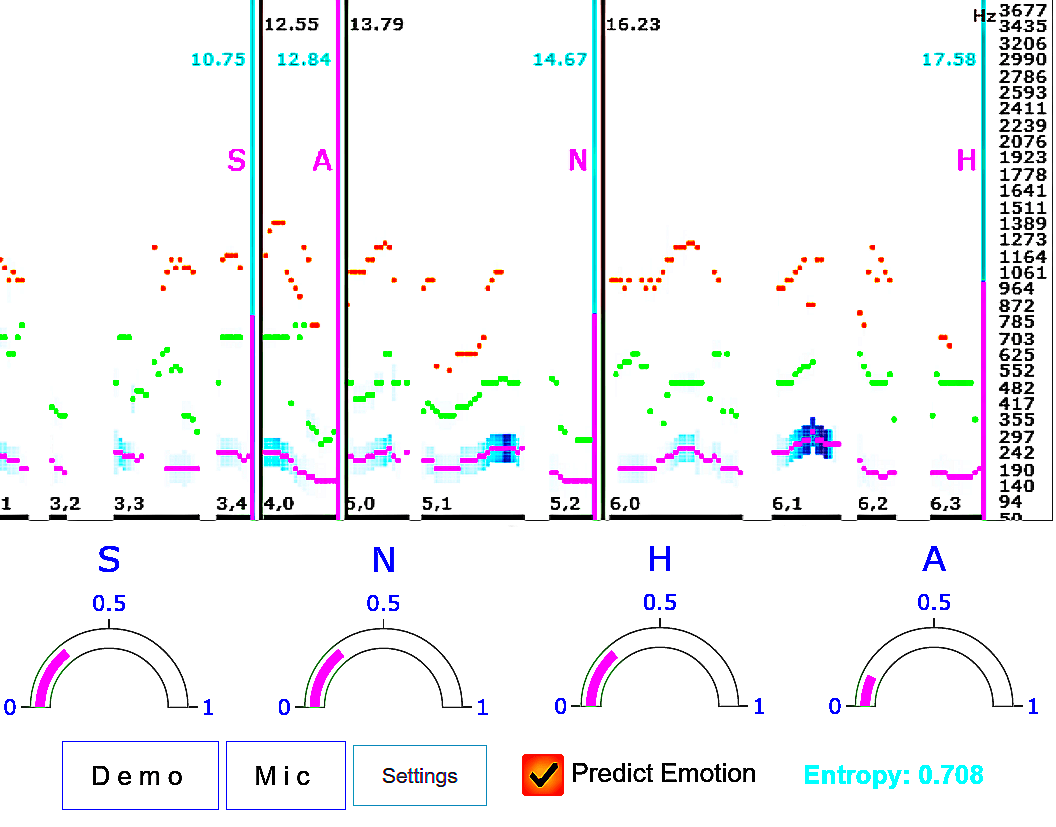
Speech emotion recognition systems have high prediction latency because of the high computational requirements for deep learning models and low generalizability mainly because of the poor reliability of emotional measurements across multiple corpora. To solve these problems, we present a speech emotion recognition system based on a reductionist approach of decomposing and analyzing syllable-level features. Mel-spectrogram of an audio stream is decomposed into syllable-level components, which are then analyzed to extract statistical features. The proposed method uses formant attention, noise-gate filtering, and rolling normalization contexts to increase feature processing speed and tolerance to adversity. A set of syllable-level formant features is extracted and fed into a single hidden layer neural network that makes predictions for each syllable as opposed to the conventional approach of using a sophisticated deep learner to make sentence-wide predictions. The syllable level predictions help to achieve the real-time latency and lower the aggregated error in utterance level cross-corpus predictions. The experiments on IEMOCAP (IE), MSP-Improv (MI), and RAVDESS (RA) databases show that the method archives real-time latency while predicting with state-of-the-art cross-corpus unweighted accuracy of 47.6% for IE to MI and 56.2% for MI to IE.
翻译:由于深层次学习模型的计算要求很高,而且由于多个公司情感测量的可靠性差,普遍程度低,因此语音识别系统具有较高的预测延迟度,因为深层次学习模型的计算要求很高,而且由于多层次公司情感测量的可靠性差,因此一般程度较低。为了解决这些问题,我们展示了一种语言情绪识别系统,其基础是分解和分析可分级特性的减少主义方法。音频流的Mel-spectrogrogram被分解成可分流成可调级的元件,随后对这些元件进行分析,以提取统计特征。拟议方法利用形成关注、噪音过滤和滚动的正常化环境环境来提高特征处理速度和逆差的耐受度。一套可调制级成功能被提取并输入到一个单一的隐蔽层神经网络,使每种音频调的预测与使用精密的深层次学习器进行全句预测的传统方法不同。可调级的级别预测有助于实现实时的延时性,并减少超临界水平跨整体预测的跨整体预测。在IMEC(IE)、IM-ISP-ISG-I-I-I-I-I)和RE-R-VI-VI-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-